Tài liệu Java Database Programming Bible- P6 ppt
Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây (1.4 MB, 50 trang )
Chapter 7:Retrieving Data with SQL Queries
-249-
* CREATE statements
*/
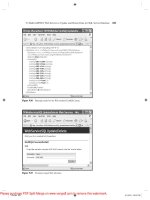
class TableQueryFrame extends JInternalFrame{
protected JTable table;
protected JScrollPane tableScroller;
protected JTextArea SQLPane = new JTextArea();
protected JButton queryButton = new JButton("Execute Query");
protected DatabaseUtilities dbUtils;
protected String tableName = null;
protected String colNames[] = null;
protected String dataTypes[] = null;
protected String SQLQuery = null;
protected String SQLCommandRoot = "";
public TableQueryFrame(String tableName, DatabaseUtilities dbUtils){
System.out.println(tableName+", "+dbUtils);
setSize(600,400);
setLocation(10,10);
setClosable(true);
setMaximizable(true);
setIconifiable(true);
setResizable(true);
getContentPane().setLayout(new BorderLayout());
this.tableName=tableName;
this.dbUtils=dbUtils;
setTitle("Query "+tableName);
init();
setVisible(true);
}
// initialize the JInternalFrame
private void init(){
TEAMFLY
Team-Fly
®
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-250-
colNames = dbUtils.getColumnNames(tableName);
dataTypes = dbUtils.getDataTypes(tableName);
SQLQuery = "SELECT TOP 5 * FROM "+tableName;
Vector dataSet = dbUtils.executeQuery(SQLQuery);
table = createTable(colNames,dataSet);
JScrollPane sqlScroller = new JScrollPane(SQLPane);
tableScroller = new JScrollPane(table);
JSplitPane splitter = new JSplitPane(JSplitPane.VERTICAL_SPLIT,
sqlScroller,tableScroller);
splitter.setDividerLocation(100);
getContentPane().add(splitter,BorderLayout.CENTER);
getContentPane().add(queryButton,BorderLayout.SOUTH);
queryButton.addActionListener(new ButtonListener());
}
protected JTable createTable(String[] colNames,Vector dataSet){
int nRows = dataSet.size();
String[][] rowData = new String[nRows][colNames.length];
for(int i=0;i<nRows;i++){
Vector row = (Vector)dataSet.elementAt(i);
for(int j=0;j<row.size();j++)
rowData[i][j]=((Object)row.elementAt(j)).toString();
}
JTable table = new JTable(rowData,colNames);
return table;
}
// Listener for the Query Button
class ButtonListener implements ActionListener{
public void actionPerformed(ActionEvent event){
SQLQuery = SQLPane.getText();
JViewport viewport = tableScroller.getViewport();
viewport.remove(table);
colNames = dbUtils.getColumnNamesUsingQuery(SQLQuery);
Vector dataSet = dbUtils.executeQuery(SQLQuery);
table = createTable(colNames,dataSet);
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-251-
viewport.add(table);
}
}
}
Changes to the DBManager class (Listing 7-4) are once again minimal, amounting to no more than
adding the hooks for the menu.
Listing 7-4: DBManager
package jdbc_bible.part2;
import java.awt.*;
import java.awt.event.*;
import java.util.Vector;
import javax.swing.*;
import javax.swing.event.*;
public class DBManager extends JFrame{
JMenuBar menuBar = new JMenuBar();
JDesktopPane desktop = new JDesktopPane();
String database = null;
String tableName = null;
String menuSelection = null;
TableBuilderFrame tableMaker = null;
TableEditFrame tableEditor = null; // added for Chapter 6
TableQueryFrame tableQuery = null; // added for Chapter 7
DatabaseUtilities dbUtils = null;
TableMenu tableMenu = new TableMenu();
EditMenu editMenu = new EditMenu(); // added for Chapter 6
ViewMenu viewMenu = new ViewMenu(); // added for Chapter 7
MenuListener menuListener = new MenuListener();
public DBManager(){
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-252 -
setJMenuBar(menuBar);
setTitle("Java Database Bible");
getContentPane().setLayout(new BorderLayout());
getContentPane().add(desktop,BorderLayout.CENTER);
setSize(new Dimension(480,320));
menuBar.add(tableMenu);
tableMenu.setMenuListener(menuListener);
menuBar.add(editMenu); // added for Chapter 6
editMenu.setMenuListener(menuListener);
menuBar.add(viewMenu); // added for Chapter 7
viewMenu.setMenuListener(menuListener);
setFont(new Font("Dialog",Font.PLAIN,18));
setVisible(true);
Font font = getGraphics().getFont();
System.out.println(font);
}
private void displayTableBuilderFrame(){
tableName = JOptionPane.showInputDialog(this,"Table:",
"Select table",JOptionPane.QUESTION_MESSAGE);
tableMaker = new TableBuilderFrame(tableName);
tableMaker.setCommandListener(new CommandListener());
desktop.add(tableMaker);
tableMaker.setVisible(true);
}
private void displayTableEditFrame(){ // added for Chapter 6
tableName = JOptionPane.showInputDialog(this,"Table:",
"Select table",JOptionPane.QUESTION_MESSAGE);
tableEditor = new TableEditFrame(tableName,dbUtils);
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-253 -
desktop.add(tableEditor);
tableEditor.setVisible(true);
}
private void displayTableQueryFrame(){ // added for Chapter 7
tableName = JOptionPane.showInputDialog(this,"Table:",
"Select table",JOptionPane.QUESTION_MESSAGE);
tableQuery = new TableQueryFrame(tableName,dbUtils);
desktop.add(tableQuery);
tableQuery.setVisible(true);
}
private String[] parseKeyValueString(String kvString){
String[] kvPair = null;
int equals = kvString.indexOf("=");
if(equals>0){
kvPair = new String[2];
kvPair[0] = kvString.substring(0,equals).trim();
kvPair[1] = kvString.substring(equals+1).trim();
}
return kvPair;
}
private void selectDatabase(){
database = JOptionPane.showInputDialog(this,"Database:",
"Select database",JOptionPane.QUESTION_MESSAGE);
dbUtils = new DatabaseUtilities();
dbUtils.setDatabaseName(database);
dbUtils.setExceptionListener(new ExceptionListener());
tableMenu.enableMenuItem("New Table",true);
tableMenu.enableMenuItem("Drop Table",true);
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-254 -
editMenu.enableMenuItem("Insert",true);
editMenu.enableMenuItem("Update",true);
editMenu.enableMenuItem("Delete",true);
viewMenu.enableMenuItem("ResultSet",true);
}
private void executeSQLCommand(String SQLCommand){
dbUtils.execute(SQLCommand);
}
private void dropTable(){
tableName = JOptionPane.showInputDialog(this,"Table:",
"Select table",JOptionPane.QUESTION_MESSAGE);
int option = JOptionPane.showConfirmDialog(null,
"Dropping table "+tableName,
"Database "+database,
JOptionPane.OK_CANCEL_OPTION);
if(option==0){
executeSQLCommand("DROP TABLE "+tableName);
}
}
class MenuListener implements ActionListener{
public void actionPerformed(ActionEvent event){
String menuSelection = event.getActionCommand();
if(menuSelection.equals("Database")){
selectDatabase();
}else if(menuSelection.equals("New Table")){
displayTableBuilderFrame();
}else if(menuSelection.equals("Drop Table")){
dropTable();
}else if(menuSelection.equals("Insert")){
displayTableEditFrame();
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-255-
}else if(menuSelection.equals("ResultSet")){ // added for Chapter 7
displayTableQueryFrame();
}else if(menuSelection.equals("Exit")){
System.exit(0);
}
}
}
class ExceptionListener implements ActionListener{
public void actionPerformed(ActionEvent event){
String exception = event.getActionCommand();
JOptionPane.showMessageDialog(null, exception,
"SQL Error", JOptionPane.ERROR_MESSAGE);
}
}
class CommandListener implements ActionListener{
public void actionPerformed(ActionEvent event){
String SQLCommand = event.getActionCommand();
executeSQLCommand(SQLCommand);
}
}
public static void main(String args[]){
DBManager dbm = new DBManager();
}
}
It now remains to add the necessary JDBC code to run the query, as discussed in the next section.
JDBC Code
In the extended version of the DatabaseUtilities class in Listing 7-5, the method
executeQuery(String SQLQuery) has been added to return a Vector of Vectors containing the
row data from the table. The choice of a Vector of Vectors is driven partly by the inherent flexibility it
offers, and partly to demonstrate an approach that differs slightly from Listing 7-1. The method
getColumnNamesUsingQuery(String SQLCommand) has also been added. This method returns a
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-256 -
String array of column names pertinent to the query, rather than all the column names for the entire
table.
Listing 7-5: DatabaseUtilities
package jdbc_bible.part2;
import java.awt.event.*;
import java.sql.*;
import java.util.Vector;
import sun.jdbc.odbc.JdbcOdbcDriver;
public class DatabaseUtilities{
static String jdbcDriver = "sun.jdbc.odbc.JdbcOdbcDriver";
static String dbName = "Contacts";
static String urlRoot = "jdbc:odbc:";
private ActionListener exceptionListener = null;
public DatabaseUtilities(){
registerDriver();
}
public void setDatabaseName(String dbName){
this.dbName=dbName;
}
public void registerDriver(){
try {
Class.forName(jdbcDriver);
DriverManager.registerDriver(new JdbcOdbcDriver());
}
catch(ClassNotFoundException e){
reportException(e.getMessage());
}
catch(SQLException e){
reportException(e.getMessage());
}
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-257-
}
public void execute(String SQLCommand){
String url = urlRoot+dbName;
try {
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
stmt.execute(SQLCommand);
con.close();
}
catch(SQLException e){
reportException(e.getMessage());
}
}
public void execute(String[] SQLCommand){
String url = urlRoot+dbName;
try {
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
for(int i=0;i<SQLCommand.length;i++){
stmt.execute(SQLCommand[i]);
}
con.close();
}
catch(SQLException e){
reportException(e.getMessage());
}
}
public String[] getColumnNames(String tableName){
Vector dataSet = new Vector();
String[] columnNames = null;
String url = urlRoot+dbName;
String SQLCommand = "SELECT * FROM "+tableName+";";
try {
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-258-
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(SQLCommand);
ResultSetMetaData md = rs.getMetaData();
columnNames = new String[md.getColumnCount()];
for(int i=0;i<columnNames.length;i++){
columnNames[i] = md.getColumnLabel(i+1);
}
con.close();
}
catch(SQLException e){
reportException(e.getMessage());
}
return columnNames;
}
public String[] getColumnNamesUsingQuery(String SQLCommand){
Vector dataSet = new Vector();
String[] columnNames = null;
String url = urlRoot+dbName;
try {
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(SQLCommand);
ResultSetMetaData md = rs.getMetaData();
columnNames = new String[md.getColumnCount()];
for(int i=0;i<columnNames.length;i++){
columnNames[i] = md.getColumnLabel(i+1);
}
con.close();
}
catch(SQLException e){
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-259 -
reportException(e.getMessage());
}
return columnNames;
}
public String[] getDataTypes(String tableName){
Vector dataSet = new Vector();
String[] dataTypes = null;
String url = urlRoot+dbName;
String SQLCommand = "SELECT * FROM "+tableName+";";
try {
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(SQLCommand);
ResultSetMetaData md = rs.getMetaData();
dataTypes = new String[md.getColumnCount()];
for(int i=0;i<dataTypes.length;i++){
dataTypes[i] = md.getColumnTypeName(i+1);
}
con.close();
}
catch(SQLException e){
reportException(e.getMessage());
}
return dataTypes;
}
public Vector executeQuery(String SQLQuery){
Vector dataSet = new Vector();
String url = urlRoot+dbName;
try {
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
TEAMFLY
Team-Fly
®
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-260-
ResultSet rs = stmt.executeQuery(SQLQuery);
ResultSetMetaData md = rs.getMetaData();
int nColumns = md.getColumnCount();
while(rs.next()){
Vector rowData = new Vector();
for(int i=1;i<=nColumns;i++){
rowData.addElement(rs.getObject(i));
}
dataSet.addElement(rowData);
}
con.close();
}
catch(SQLException e){
reportException(e.getMessage());
}
return dataSet;
}
public void setExceptionListener(ActionListener exceptionListener){
this.exceptionListener=exceptionListener;
}
private void reportException(String exception){
if(exceptionListener!=null){
ActionEvent evt = new ActionEvent(this,0,exception);
exceptionListener.actionPerformed(evt);
}else{
System.err.println(exception);
}
}
}
Summary
In this chapter you learned how to build and use queries and subqueries. You also learned how to use
queries and subqueries in a SELECT command as well as in the INSERT, DELETE, and UPDATE
commands. Other topics discussed were:
§ What a Query is and how to create and execute one
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 7:Retrieving Data with SQL Queries
-261 -
§ Using SELECT FROM to retrieve all rows and columns from a table
§ Using the WHERE clause to retrieve rows matching a specific query
§ Using the ORDER BY clause to sort the returned data
§ SQL Operators
§ Escape sequences
§ Subqueries using the keywords:
§ EXISTS and NOT EXISTS
§ ANY and ALL
§ IN and NOT IN
§ Nested and correlated subqueries
§ JDBC ResultSets and ResultSetMetaData
The next chapter discusses using joins to retrieve data from more than one table.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-262-
Chapter 8: Organizing Search Results and Using
Indexes
In This Chapter
This chapter discusses various ways of organizing and analyzing the data returned by SQL queries.
These include sorting the data by one or more columns, grouping the data and performing statistical
analysis, and filtering the grouped results.
The chapter also addresses the use of indexes to make your queries more efficient. Using indexes
wisely can result in a very significant improvement in performance, while using indexes incorrectly can
result in very poor performance.
The final topic discussed in this chapter is the use of Views. Views provide a means of creating
temporary tables based on a particular query.
Using ORDER BY to Sort the Results of a Query
A common requirement when retrieving data from an RDBMS by using the SELECT statement is to sort
the results of the query in alphabetic or numeric order on one or more of the columns. You sort the
results by using the ORDER BY clause in a statement like this:
SELECT First_Name, Last_Name, City, State
FROM CUSTOMERS
WHERE Last_Name = 'Corleone'
ORDER BY First_Name;
This gives you a list of all the Corleones sorted in ascending order by first name, as shown in Table
8-1:
Table 8-1: Records Sorted Using ORDER BY
First_Name Last_Name City State
Francis Corleone New York NY
Fredo Corleone New York NY
Michael Corleone New York NY
Sonny Corleone Newark NJ
Vito Corleone Newark NJ
The default sort order is ascending. This can be changed to descending order by adding the DESC
keyword as shown in the next example:
Note
The keywords ASC and DESC can be used to specify ascending or descending sort
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-263-
order.
SELECT *
FROM CUSTOMERS
WHERE Last_Name = 'Corleone'
ORDER BY First_Name DESC;
Sorting on multiple columns is also easy to do by using a sort list. For example, to sort the data in
ascending order based on Last_Name and then sort duplicates using the First_Name in descending
order, the sort list is as follows:
ORDER BY Last_Name, First_Name DESC;
The entire SQL statement to sort the data in ascending order based on Last_Name and then sort
duplicates using the First_Name in descending order is shown below .
SELECT First_Name, MI, Last_Name, Street, City, State, Zip
FROM CUSTOMERS
ORDER BY Last_Name, First_Name DESC;
Note
When no ORDER BY clause is used, the order of the output of a query is undefined.
These are the rules for using ORDER BY:
§ ORDER BY must be the last clause in the SELECT statement.
§ Default sort order is ascending.
§ You can specify ascending order with the keyword ASC.
§ You can specify descending order with the keyword DESC.
§ You can use column names or expressions in the ORDER BY clause.
§ The column names in the ORDER BY clause do not have to be specified in the select list.
§ NULLS usually occur first in the sort order.
Note
The DatabaseMetaData object provides a number of methods:
boolean nullsAreSortedAtStart()
boolean nullsAreSortedAtEnd()
These methods can be used to determine the sort order for NULLs when in doubt.
Another common reporting requirement is to break down the data a query returns into various groups
so that the data can be analyzed in some way. The GROUP BY clause, discussed in the next section,
enables you to combine database records to perform calculations such as averages or counts on
groups of records.
The GROUP BY Clause
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-264-
The GROUP BY clause combines records with identical values in a specified field into a single record for
this purpose, as shown in Figure 8-1, illustrating how to use GROUP BY to compute a count of
customers by state.
Figure 8-1: Using GROUP BY to count customers by state
Because the GROUP BY clause combines all records with identical values in one column into a single
record, each of the column names in the SELECT clause must be either a column specified in the
GROUP BY clause or a column function such as COUNT() or SUM().
This means that you can't SELECT a list of individual customers by name and then count them as a
group by using GROUP BY. However, you can group on more than one column, just as you can use
more than one column with the ORDER BY clause. You can see an example of the use of GROUP BY on
more than one column in Figure 8-2.
Figure 8-2: Using GROUP BY on multiple columns
Note
Every column name specified in the SELECT statement is also mentioned in the GROUP
BY clause. Not mentioning the column names in both places gives you an error. The
GROUP BY clause returns a row for each unique combination of description and state.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-265-
The most important uses of the GROUP BY clause is to group data for analytical purposes. The
functions used to analyze groups of data are called aggregate functions. The aggregate functions are
discussed in the next section.
Aggregate Functions
Aggregate functions return a single value from an operation on a column of data. This differentiates
them from the arithmetic, logical, and character functions discussed in Chapter 7, which operate on
individual data elements. Most relational database management systems support the aggregate
functions listed in Table 8-2.
Table 8-2: Commonly Supported Aggregate Functions
Sum
SUM
Average
AVG
Count
COUNT
Standard Deviation
STDEV
Maximum
MAX
Minimum
MIN
Aggregate functions are used to provide statistical or summary information about groups of data
elements. These groups may be created specifically using the GROUP BY clause, or the aggregate
functions may be applied to the default group, which is the entire result set.
A good practical example of the use of aggregate functions is the creation of a simple sales report. In
Figure 8-3, the query creates a result set listing distinct customers and calculating the number and total
cost of the items they have bought.
Figure 8-3: Using aggregate functions
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-266-
Since this example groups order data by customer, each row of the result set represents a single
customer so that customer information can be displayed. The aggregate functions act on all the
purchases customers have made, so they, too, can be included in the SELECT list:
Note
The fundamental difference between aggregate functions and standard functions is that
aggregate functions use the entire column of data as their input and produce a single
output, whereas standard functions operate on individual data elements .
In addition to using the GROUP BY clause to group your results, you may also wish to narrow your set of
groups down to a smaller subset. You can filter grouped data by using the HAVING clause, which is
discussed in the next section.
Using the HAVING Clause to Filter Groups
There are going to be situations where you'll want to filter the groups themselves in much the same
way as you filter records using the WHERE clause. For example, you may want to analyze your sales by
state but ignore states with a limited number of customers.
SQL provides a way of filtering groups in a result set using the HAVING clause. The HAVING clause
works in much the same way as the WHERE clause, except that it applies to groups within a returned
result set, rather than to the entire table or group of tables forming the subject of a SELECT statement.
To filter groups, apply a HAVING clause after the GROUP BY clause. The HAVING clause lets you apply
a qualifying condition to groups so that the database management system returns a result only for the
groups that satisfy the condition. Incidentally, you can also apply a HAVING clause to the entire result
set by omitting the GROUP BY clause. In this case, DBMS treats the entire table as one group, so there
is at most one result row. If the HAVING condition is not true for the table as a whole, no rows will be
returned.
HAVING clauses can contain one or more predicates connected by ANDs and ORs. Each predicate
compares a property of the group (such as COUNT(State)) with either another property of the group
or a constant.
Figure 8-4 shows the use of the HAVING clause to compute a count of customers by state, filtering
results from states that contain only one customer.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-267 -
Figure 8-4: Using the HAVING clause
The main similarity between the HAVING clause and the WHERE clause is that both allow you to use a
variety of filters in a query. The main difference is that the HAVING clause applies to groups within a
returned result set, while the WHERE clause applies to the entire table or group of tables forming the
subject of a SELECT statement.
Using Indexes to Improve the Efficiency of SQL Queries
You can improve database performance significantly by using indexes. An index is a structure that
provides a quick way to look up specific items in a table or view. In effect, an index is an ordered array
of pointers to the rows in a table or view.
When you assign a unique id to each row as a key, you are predefining an index for that table. This
makes it much faster for the DBMS to look up items by id, which is commonly required when you are
doing joins on the id column.
SQL's CREATE INDEX statement allows you to add an index for any desired column or group of
columns. When you need to do a search by customer name, for example, the unique row id buys you
nothing; the DBMS has to do a brute-force search of the entire table to find all customer names
matching your query. If you plan on doing a lot of queries by customer name, it obviously makes sense
to add an index to the customer name column or columns. Otherwise, you are in the position of
someone working with a phone list that hasn't been alphabetized.
The SQL command to add an index uses the CREATE INDEX keyword, specifying a name for the index
and defining the table name and the column list to index. Here's an example:
CREATE INDEX STATE_INDEX ON MEMBER_PROFILES(STATE);
To remove the index, use the DROP INDEX command.
DROP INDEX MEMBER_PROFILES.STATE_INDEX;
Notice how the name of the index has to be fully defined by prefixing it with the name of the table to
which it applies.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-268-
The example in Listing 8-1 is a simple JDBC, with a couple of lines of additional code that calculate the
start and stop times of the query so that the elapsed can be calculated. By commenting out the
CREATE INDEX and DROP INDEX lines, speed improvement can easily be calculated.
Listing 8-1: Creating and dropping indexes
package java_databases.ch04;
import java.sql.*;
public class PrintIndexedResultSet{
public static void main(String args[]){
String query =
"SELECT STATE, COUNT(STATE) FROM MEMBER_PROFILES GROUP BY STATE";
PrintIndexedResultSet p = new PrintIndexedResultSet(query);
}
public PrintIndexedResultSet(String query){
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection con = DriverManager.getConnection ("jdbc:odbc:Members");
Statement stmt = con.createStatement();
stmt.executeUpdate("CREATE INDEX STATE_INDEX ON
MEMBER_PROFILES(STATE)");
java.util.Date startTime = new java.util.Date();
ResultSet rs = stmt.executeQuery(query);
ResultSetMetaData md = rs.getMetaData();
int nColumns = md.getColumnCount();
for(int i=1;i<=nColumns;i++){
System.out.print(md.getColumnLabel(i)+((i==nColumns)?"\n":"\t"));
}
while (rs.next()) {
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-269-
for(int i=1;i<=nColumns;i++){
System.out.print(rs.getString(i)+((i==nColumns)?"\n":"\t"));
}
}
java.util.Date endTime = new java.util.Date();
long elapsedTime = endTime.getTime() - startTime.getTime();
System.out.println("Elapsed time: "+elapsedTime);
stmt.executeUpdate("DROP INDEX MEMBER_PROFILES.STATE_INDEX");
}
catch(ClassNotFoundException e){
e.printStackTrace();
}
catch(SQLException e){
e.printStackTrace();
}
}
}
The example in Listing 8-1 is run against a membership database containing approximately 150,000
members and shows an improvement of 2:1 in elapsed time for the query shown.
Once you have executed a SQL query and obtained a sorted, grouped set of data from the database, it
is frequently very useful to be able to save the query for reuse. One of the ways SQL lets you do this is
by using Views.
Views
A view is similar to a table, but rather than being created as a fundamental part of the underlying
database, it is created from the results of a query. In fact, you can think of a view as a temporary table.
Like a table, a view has a name that can be used to access it in other queries. Because views work like
tables, they can be a very useful tool in simplifying SQL queries. For example, you could create a view
based on a complex JOIN, and then work with that view as a temporary table rather than embedding
the JOIN as a subquery and working with the underlying tables.
The basic syntax used to create a view is as follows:
CREATE VIEW Orders_by_Name AS SELECT
The SELECT statement in the code is the SELECT you use in the query you want to save as a view, as
shown here:
TEAMFLY
Team-Fly
®
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-270-
CREATE VIEW ViewCorleones AS
SELECT *
FROM CUSTOMERS
WHERE Last_Name = 'Corleone'
Now you can execute a query just as if this view were a normal table, as follows:
SELECT *
FROM ViewCorleones
The result set this query returns looks like this:
FIRST_NAME MI LAST_NAME STREET CITY STATE ZIP
Michael A Corleone 123 Pine New York NY 10006
Fredo X Corleone 17 Main New York NY 10007
Sonny A Corleone 123 Walnut Newark NJ 12346
Francis X Corleone 17 Main New York NY 10005
Vito G Corleone 23 Oak St Newark NJ 12345
As with any other table, you can use more complex queries. Here's an example:
SELECT *
FROM ViewCorleones
WHERE State = 'NJ'
This query returns the following result set:
FIRST_NAME MI LAST_NAME STREET CITY STATE ZIP
Sonny A Corleone 123 Walnut Newark NJ 12346
Vito G Corleone 23 Oak St Newark NJ 12345
You can use a view for updating or deleting rows, as well as for retrieving data. Since the view is not a
table in its own right, but merely a way of looking at a table, rows updated or deleted in the view are
updated or deleted in the original table. For example, you can use the view to change Fredo
Corleone's street address by using the following SQL statement:
UPDATE ViewCorleones
SET Street = '19 Main'
WHERE First_Name = 'Fredo'
This example illustrates one of the advantages of using a view. A lot of the filtering required to identify
the target row is done in the view, so the SQL code is simpler and more maintainable. In a nontrivial
example, this can be a worthwhile improvement.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-271 -
Figure 8-5 shows how using the view to the change Fredo Corleone's street address propagates
through to the Customers Table.
Figure 8-5: Updating a view updates the underlying table.
Recall that a view is really nothing more than a named result set made accessible as if it were a table.
Creating a view from a complicated query is just as easy as creating one from a simple query.
One way to retrieve data from multiple tables is to use an INNER JOIN. The next example shows how
to use an INNER JOIN to retrieve data from four different tables, creating a view called
"Orders_by_Name":
CREATE VIEW Orders_by_Name AS
SELECT c.LAST_NAME + ', ' + c.FIRST_NAME AS Name,
COUNT(i.Item_Number) AS Items, SUM(oi.Qty * i.Cost)
AS Total
FROM ORDERS o INNER JOIN
ORDERED_ITEMS oi ON
o.Order_Number = oi.Order_Number INNER JOIN
INVENTORY i ON
oi.Item_Number = i.Item_Number INNER JOIN
CUSTOMERS c ON
o.Customer_Number = c.CUSTOMER_NUMBER
GROUP BY c.LAST_NAME + ', ' + c.FIRST_NAME
Cross-Reference
JOINS are discussed in Chapter 9.
You can now query this view in the normal way to get a summary of customer orders by name as
shown in the following table.
Name Items Total
Adams, Kay 3 6.96
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 8:Organizing Search Results and Using Indexes
-272-
Name Items Total
Corleone, Francis 2 7.42
Corleone, Fredo 4 12.92
Corleone, Vito 2 13.45
This result set always reflects the underlying table; if Fredo Corleone were to buy a huge supply of
chocolate chip cookies, the next time you run the same query, you might see a result set like this one:
Name Items Total
Adams, Kay 3 6.96
Corleone, Francis 2 7.42
Corleone, Fredo 4 135.14
Corleone, Vito 2 13.45
Note
Views are a way of saving queries by name, which can be very useful for creating reports
or updates you want to use on a regular basis. The database management system
generally saves the view by associating the SELECT statement with the view name and
executing it when you want to access the view.
Summary
In this chapter, you learn to perform the following tasks:
§ Sorting the data you retrieve from a database
§ Grouping the results for analysis
§ Performing statistical analyses on the data you retrieve from a database
§ Create and use indexes to improve performance
§ Saving your queries as views
In the next chapter, you learn to retrieve data from more than one table.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.
Chapter 9:Joins and Compound Queries
-273-
Chapter 9: Joins and Compound Queries
In This Chapter
One of the most powerful features of SQL is its ability to combine data from several tables into a single
result set. When tables are combined in this way, the operation performed is called a JOIN. There are
two primary types of JOIN, and a number of different ways in which they can be performed.
Another way to combine data from different tables into a single result set is to use the UNION operator.
This chapter discusses the different types of JOINS, and the use of the UNION operator.
Joining Tables
Chapter 2 explained how an efficient and reliable database design frequently requires the information
in a practical database will be distributed across several tables, each of which contains sets of logically
related data. A typical example might be a database containing these four tables:
§ Customers, containing customer number, name, shipping address, and billing information
§ Inventory, containing item number, name, description, cost, and quantity on hand
§ Orders, containing order number, customer number, order date, and ship date
§ Ordered_Items, containing order number, item number, and quantity
When a customer places an order, an entry is made in the Orders Table, assigning an order number
and containing the customer number and the order date. Then entries are added to the Ordered_Items
table, recording order number, item number, and quantity. To fill a customer order, you need to
combine the necessary information from each of these tables.
Using JOIN, you are able to combine data from these different tables to produce a detailed invoice.
This invoice will show the customer name, shipping address, and billing information from the
Customers table, combined with a detailed list of the items ordered from the Ordered_Items table,
supported by detailed description, quantity, and unit price information from the inventory table.
Cross-Reference
Primary and Foreign Keys are also discussed in Chapter 1, which provides
a more theoretical overview of Relational Database Management Systems.
Types of Joins
There are two major types of Joins: Inner Joins and Outer Joins. The difference between these two
types of Joins goes back to the basic Set Theory underlying relational databases. You can imagine the
keys of two database tables, A and B as intersecting sets, as shown in Figure 9-1.
Please purchase PDF Split-Merge on www.verypdf.com to remove this watermark.