Tìm hiểu về nhận dạng ảnh
Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây (1.31 MB, 30 trang )
ĐẠI HỌC QUỐC GIA THÀNH PHỐ HỒ CHÍ MINH
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ THÔNG TIN
KHOA CÔNG NGHỆ PHẦN MỀM
BÁO CÁO ĐỒ ÁN 1
ĐỀ TÀI: Tìm hiểu về nhận dạng ảnh
Giảng viên hướng dẫn:
Thầy Mai Trọng Khang
Sinh viên thực hiện:
Sơn Ngọc Minh
19521853
Phạm Hiểu Vy
19520358
Tp. Hồ Chí Minh, tháng 12 năm 2021
1
LỜI CẢM ƠN
Lời đầu tiên, em xin bày tỏ lòng biết ơn sâu sắc đến thầy Mai Trọng Khang –
Giảng viên hướng dẫn chúng em thực hiện Đồ án 1, thầy đã cùng đồng hành và tận
tình hướng dẫn cho chúng em qua từng giai đoạn của đồ án. Nhờ có sự giúp đỡ
nhiệt tình của thầy mà chúng em có thể hồn thành được được đồ án này một cách
tốt nhất. Vì kiến thức của chúng em vẫn cịn hạn hẹp nên khơng thể tránh khỏi
những thiếu sót trong quá trình thực hiện đồ án. Tuy nhiên, chúng em đã cố gắng
hoàn thành đúng hạn và hạn chế các lỗi nhiều nhất có thể. Nhóm chúng em ln
mong đợi nhận được những ý kiến đóng góp quý báu từ thầy và qua đó có thể rút
kinh nghiệm, tự sửa chữa, hồn thiện bản thân mình trên tinh thần nghiêm túc, tự
giác học hỏi. Trong quá trình làm đề tài báo cáo, sẽ khơng thể tránh khỏi các thiếu
sót, rất mong nhận được phản hồi từ thầy và các bạn để góp phần làm cho bản báo
cáo thêm hồn thiện hơn.
Chân thành cảm ơn thầy!
2
NHẬN XÉT
(Của giảng viên hướng dẫn)
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
3
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
Mở đầu .................................................................................................................................................. 6
I.
1.
Lý do chọn đề tài............................................................................................................................... 6
2.
Mục tiêu nghiên cứu ......................................................................................................................... 6
3.
Phương pháp nghiên cứu................................................................................................................... 6
II.
Machine learning .................................................................................................................................. 6
1.
Tổng quan ......................................................................................................................................... 6
2.
Phân loại thuật toán ML .................................................................................................................... 7
2.1. Phân loại dựa trên phương thức học .............................................................................................. 7
a.
Học có giám sát ......................................................................................................................... 7
b.
Học không giám sát................................................................................................................... 7
c.
Học bán giám sát ....................................................................................................................... 7
d.
Học củng cố .............................................................................................................................. 8
2.2. Phân loại dựa trên thuật toán.......................................................................................................... 8
2.2.1. Regression Algorithms ............................................................................................................ 8
a.
Linear Regression ............................................................................................................... 8
b.
Logistic Regression ............................................................................................................. 8
c.
Stepwise Regression ............................................................................................................ 9
2.2.2. Classification Algorithms ....................................................................................................... 9
a.
Linear Classifier .................................................................................................................. 9
b.
Support Vector Machine (SVM) ...................................................................................... 10
4
c.
Kernel SVM ....................................................................................................................... 10
2.2.3. Instance-based Algorithms.................................................................................................... 10
a.
K-Nearest Neighbor (KNN).............................................................................................. 10
b.
Learning Vector Quantization (LVQ) ............................................................................. 11
2.2.4. Clustering Algorithms ........................................................................................................... 12
a.
K-Means clustering ........................................................................................................... 12
b.
K-Medians ......................................................................................................................... 12
2.2.5 Artificial Neural Network Algorithms ................................................................................... 13
a.
Perceptron ......................................................................................................................... 13
b.
Softmax Regression ........................................................................................................... 13
c.
Multi-layer Perceptron ..................................................................................................... 13
2.2.6.
Dimensionality Reduction Algorithm ............................................................................. 14
a.
Principal Component Analysis (PCA) ............................................................................. 14
b.
Linear Discriminant Analysis (LDA) .............................................................................. 15
III. Bài toán nhận dạng tiền mặt.................................................................................................................. 15
1.
Keras ........................................................................................................................................... 15
2.
Convolutional Neutral Network (CNN) ...................................................................................... 16
3.
VGG16 ........................................................................................................................................ 21
4.
Transfer Learning........................................................................................................................ 22
5.
Các bước thực hiện chính của bài tốn nhận diện tiền mặt ......................................................... 22
IV. Kết luận và hướng phát triển ................................................................................................................ 29
1.
Kết quả đạt được ........................................................................................................................... 29
2.
Hạn chế .......................................................................................................................................... 29
3.
Hướng phát triển........................................................................................................................... 30
TÀI LIỆU THAM KHẢO .......................................................................................................................... 30
5
I.
Mở đầu
1. Lý do chọn đề tài
Machine Learning là một trong những thuật ngữ mà chúng ta thường hay nghe đến trong
lĩnh vực công nghệ thông tin cụ thể hơn là trí tuệ nhân tạo. Thực chất đây chính là một lĩnh vực
của trí tuệ nhân tạo, là một lĩnh vực quan trọng trong khoa học máy tính, được ứng dụng rộng rãi
trong khắp các lĩnh vực đời sống trong nền cách mạng công nghiệp 4.0.
Hiện nay, Machine Learning tỏ ra cực kỳ hiệu quả, hơn hẳn con người trong cụ thể lĩnh vực
mà chúng được áp dụng. Trong số đó khơng thể khơng kể đến như nhận dạng ảnh, chẩn đốn y
khoa, dự báo thời tiết, …
Vì vậy, khi nhận thấy được nhận dạng ảnh là một lĩnh vực ngày càng phổ biến, có tính ứng
dụng cao và rộng rãi với nhiều mặt trong cuộc sống. Nhóm em đã quyết định chọn đề tài tìm hiểu
về nhận dạng ảnh và cụ thể hơn là nhận dạng tiền mặt sử dụng thư viện Keras và mạng CNN
(VGG16).
2. Mục tiêu nghiên cứu
Mục tiêu nghiên cứu của đồ án là tìm khái quát về Machine Learning và nhận dạng ảnh. Qua
đó xây dựng, huấn luyện một mơ hình Machine Learning nhận dạng tiền mặt đơn giản.
3. Phương pháp nghiên cứu
Qua việc tham khảo các tài liệu trên Internet và sự chỉ dẫn của giảng viên, nhóm em đã xây
dựng một hệ thống nhận diện tiền mặt đơn giản dựa trên mạng VGG16 và kĩ thuật Transfer
Learning với sự hỗ trợ từ thư viện Keras.
II.
Machine learning
1. Tổng quan
Machine Learning là một tập con của AI (Artificial Intelligence – Trí tuệ nhân tạo). Nói đơn
giản thì Machine Learning là một lĩnh vực nhỏ của Khoa học máy tính, nó có khả năng tự học hỏi
dựa trên dữ liệu đưa vào mà không cần phải lập trình cụ thể. Machine Learning làm cho máy tính
có những khả năng nhận thức cơ bản của con người như nghe, nhìn, hiểu được ngơn ngữ, giải
tốn, lập trình, … và hỗ trợ con người trong việc xử lý một khối lượng lớn thông tin khổng lô mà
chúng ta phải đối mặt hằng ngày, hay còn gọi là Big Data.
6
2. Phân loại thuật toán ML
2.1. Phân loại dựa trên phương thức học
a. Học có giám sát
Học có giám sát (Supervised Learning) là mơ hình học sử dụng thuật tốn dự đoán đầu ra
(outcome) của một dữ liệu mới (new input) dựa trên các cặp (input, outcome) đã biết từ trước.
Cặp dữ liệu này còn được gọi là (observation, label) trong đó :
-
Observation : kí hiệu là x, input trong các bài tốn. Observation thường có dạng một
vector x = (x1, x2, …, xn), gọi là feature vector. Mỗi xi gọi là một feature.
Label : kí hiệu là y, output của bài tốn. Mỗi observation sẽ có một label tương ứng tạo
thành cặp (observation, label)
Các cặp dữ liệu (input, outcome) biết trước được gọi là training data (dữ liệu huấn luyện)
Học có giám sát mơ phỏng việc con người học bằng cách đưa ra dự đốn của mình cho một
câu hỏi, sau đó đối chiếu với đáp án. Sau đó rút ra phương pháp để trả lời đúng không chỉ câu hỏi
đó, mà cho những câu hỏi có dạng tương tự.
Trong học có giám sát, các observation bắt buộc phải được dán nhãn trước. Đây chính là
một nhước điểm của phương pháp này, bởi vì khơng phải lúc nào việc dán nhãn chính xác cho
observation cũng dễ dàng.
Học có giám sát thường được chia làm 2 loại :
-
Phân loại (Classification): Một bài toán được gọi là classification nếu các label của input
data được chia thành một số hữu hạn nhóm.
Hồi quy (Hồi quy): Khi đầu ra mong muốn là một dải giá trị liên tục hoặc một giá trị thực.
Chẳng hạn như "tiền lương" hay "trọng lượng". Mơ hình hồi quy đơn giản nhất là hồi quy
tuyến tính.
Học có giám sát là mơ hình học phổ biến nhất trong Machine Learning.
b. Học không giám sát
Học không giám sát là một lớp mơ hình học sử dụng một thuật tốn để mơ tả hoặc trích xuất
ra các mối quan hệ tiềm ẩn trong dữ liệu. Khác với học có giám sát, học không giám sát chỉ thực
thi trên dữ liệu đầu vào khơng cần các thuộc tính nhãn, hoặc mục tiêu của việc học. Mơ hình
khơng hề được cung cấp trước một kiến thức nào trừ dữ liệu. Các dữ liệu khơng được "hướng
dẫn" trước như học có giám sát. Các thuật tốn cần học được từ dữ liệu mà khơng hề có bất cứ sự
hướng dẫn nào.
c. Học bán giám sát
Học bán giám sát là mơ hình học kết hợp từ học có giám sát và học khơng giám sát bằng
việc gán nhãn cho một số dữ liệu và một số dữ liệu thì lại khơng được gán nhãn trong đó số lượng
dữ liệu khơng được gán nhãn thường lớn hơn nhiều so với dữ liệu được gán nhãn. Các dữ liệu
7
này được kết hợp với nhau để tận dụng hiệu quả dữ liệu có được. Thơng thường, điều này sẽ làm
tăng tính chính xác của mơ hình xây dựng.
d. Học củng cố
Học tăng cường (Reinforcement Learning) là mơ hình học trong đó thuật tốn tự động sử
dụng các phản hồi từ mơi trường để điều chỉnh hoạt động của chính mình sao cho tối đa nhất hiệu
quả đạt được. Thuật tốn reinforcement learning sẽ đo các phản hồi từ mơi trường và sử dụng một
hàm đánh giá để tìm các phương án hành động nhằm tăng cường phản hồi tích cực từ mơi trường.
Trong mơ hình này, khơng có tập huấn luyện cố định, thuật toán chỉ cần một mục tiêu hoặc một
nhóm các mục tiêu cần đạt, tập các hành vi có thể thực hiện, và dữ liệu phản hồi về hiệu quả thực
thi của các hành động so với mục tiêu đề ra.
2.2. Phân loại dựa trên thuật tốn
2.2.1. Regression Algorithms
a. Linear Regression
Hồi quy tuyến tính (Linear Regression) là thuật tốn tìm ra phương trình tuyến tính dựa trên
tập dữ liệu quan hệ giữa X (dữ liệu đầu vào) và Y (dữ liệu đầu ra). X là biến giải thích và Y là
biến phụ thuộc. Ví dụ, tạo ra mơ hình quan hệ giữa chiều cao và cân nặng bằng mơ hình hồi quy
tuyến tính. Trước khi thử tạo ra mơ hình quan hệ, nên xác định liệu giữa các mối quan hệ này có
liên quan với nhau hay khơng. Khơng nhất thiết phải có sự tương tác giữa các biến, nhưng cần
phải có sự liên quan. Để chỉ ra mối quan hệ giữa các biến có thể dùng biểu đồ phân tán như một
công cụ trong việc xác định mức độ liên quan. Nếu khơng có mối quan hệ nào giữa các biến được
đưa vào mơ hình, thì mơ hình hồi quy tuyến tính sẽ khơng giúp ích được trong trường hợp này.
Hình 1 Linear Regression
b. Logistic Regression
Hồi quy logistic (Logistic Regression) là 1 thuật toán phân loại được dùng để gán các đối
tượng cho 1 tập hợp giá trị rời rạc (như 0, 1, 2, ...). Một ví dụ điển hình là phân loại Email, gồm
8
có email cơng việc, email gia đình, email spam, ... Giao dịch trực tuyến có là an tồn hay khơng
an tồn, khối u lành tính hay ác tình. Thuật tốn trên dùng hàm sigmoid logistic để đưa ra đánh
giá theo xác suất. Ví dụ : Khối u này 80% là lành tính, giao dịch này 90% là gian lận, ...
Ứng dụng:
+ Dự đốn email có phải spam hay khơng.
+ Dự đốn giao dịch ngân hàng là gian lận hay khơng.
+ Dự đốn khối u lành hay ác tính.
+ Dự đốn khoản vay có trả được khơng.
+ Dự đốn khoản đầu tư vào start-up có sinh lãi hay khơng.
c. Stepwise Regression
Hồi quy từng bước (stepwise regression) là dạng phân tích hồi quy bội trong đó các biến độc lập được bổ
sung dần dần (từng biến một) vào phương trình hồi quy và ảnh hưởng của chúng tính bằng mức bổ sung
và khả năng giải thích của phương trình hồi quy được ghi lại.
Nhược điểm lớn nhất của phương pháp quy hồi từng bước là cho phép các biến khơng có liên quan vào
trong mơ hình, do vậy, hồi quy Stepwise có thể tạo ra các mối quan hệ ảo hay tác động giả lên biến phụ
thuộc trong mơ hình.
Phương pháp quy hồi từng bước chỉ được khuyến khích sử dụng khi các biến đưa vào trong mơ hình được
sử hỗ trợ vững chắc của các lý thuyết liên quan đến vấn đề nghiên cứu. Trong trường hợp này, để đánh
giá sự cải thiện độ phù hợp của mơ hình thơng qua các chỉ số như R – bình phương hoặc các chỉ số thơng
tin như AIC, BIC ở mỗi bước thì chúng ta có thể sử dụng câu lệnh nestreg để ghi nhận sự thay đổi của các
chỉ số này. Câu lệnh nestreg cho biết rất nhiều thông tin về độ phù hợp của mơ hình như thống kê Wald,
Chi – bình phương, R – bình phương, sự thay đổi R – bình phương cũng như các chỉ số thơng tin AIC,
BIC cho mỗi mơ hình trung gian.
2.2.2. Classification Algorithms
a. Linear Classifier
Trong lĩnh vực machine learning, mục tiêu của phân loại thống kê là sử dụng các đặc điểm của một đối
tượng để xác định nó thuộc về lớp nào. Một bộ phân loại tuyến tính đạt được điều này bằng cách đưa ra
quyết định phân loại dựa trên giá trị của sự kết hợp tuyến tính của các đặc tính.
Đặc điểm của một đối tượng còn được gọi là giá trị đặc trưng và thường được trình bày cho máy trong
một vectơ được gọi là vectơ đặc trưng. Các bộ phân loại như vậy hoạt động tốt cho các vấn đề thực tế như
phân loại tài liệu và nói chung là cho các vấn đề có nhiều biến (tính năng), đạt đến mức độ chính xác
tương đương với bộ phân loại phi tuyến tính trong khi mất ít thời gian hơn để đào tạo và sử dụng.
9
Hình 2 Linear Classifier
b. Support Vector Machine (SVM)
Trong machine learning, support-vector machines (SVMs, cũng là support-vector networks) là mơ hình
học có giám sát với các thuật tốn học liên quan phân tích dữ liệu để phân loại và phân tích hồi quy.
Ngồi việc thực hiện phân loại tuyến tính, SVM có thể thực hiện phân loại phi tuyến tính một cách hiệu
quả bằng cách sử dụng cái được gọi là thủ thuật hạt nhân, ánh xạ ngầm các đầu vào của chúng vào không
gian đặc trưng chiều cao.
Khi dữ liệu khơng được gắn nhãn, việc học có giám sát là khơng thể thực hiện được và cần có phương
pháp học tập khơng có giám sát nhằm tìm cách phân cụm dữ liệu tự nhiên thành các nhóm, sau đó ánh xạ
dữ liệu mới tới các nhóm đã hình thành này.
c. Kernel SVM
Ý tưởng cơ bản của Kernel SVM và các phương pháp kernel nói chung là tìm một phép biến đổi sao cho
dữ liệu ban đầu là không phân biệt tuyến tính được biến sang khơng gian mới. Ở khơng gian mới này, dữ
liệu trở nên phân biệt tuyến tính.
Nếu dữ liệu của hai lớp là không phân biệt tuyến tính, chúng ta có thể tìm cách biến đổi dữ liệu sang một
không gian mới sao cho trong không gian mới ấy, dữ liệu của hai lớp là phân biệt tuyến tính hoặc gần
phân biệt tuyến tính.
Có 4 loại kernel thơng dụng: linear, poly, rbf, sigmoid. Trong đó, rbf được sử dụng nhiều nhất và là lựa
chọn mặc định trong các thư viện SVM. Với dữ liệu gần phân biệt tuyến tính, linear và poly kernels cho
kết quả tốt hơn.
2.2.3. Instance-based Algorithms
a. K-Nearest Neighbor (KNN)
10
K-nearest neighbor là một trong những thuật toán supervised-learning đơn giản nhất (mà hiệu quả trong
một vài trường hợp) trong Machine Learning. Khi training, thuật tốn này khơng học một điều gì từ dữ
liệu training, mọi tính tốn được thực hiện khi nó cần dự đốn kết quả của dữ liệu mới. K-nearest
neighbor có thể áp dụng được vào cả hai loại của bài toán Supervised learning là Classification và
Regression.
Trong bài toán Classification, label của một điểm dữ liệu mới suy ra trực tiếp từ K điểm dữ liệu gần nhất
trong training set. Label của một test data có thể được quyết định bằng major voting (bầu chọn theo số
phiếu) giữa các điểm gần nhất, hoặc nó có thể được suy ra bằng cách đánh trọng số khác nhau cho mỗi
trong các điểm gần nhất đó rồi suy ra label.
Trong bài toán Regresssion, đầu ra của một điểm dữ liệu sẽ bằng chính đầu ra của điểm dữ liệu đã biết
gần nhất (trong trường hợp K=1), hoặc là trung bình có trọng số của đầu ra của những điểm gần nhất,
hoặc bằng một mối quan hệ dựa trên khoảng cách tới các điểm gần nhất đó.
Một cách ngắn gọn, KNN là thuật tốn đi tìm đầu ra của một điểm dữ liệu mới bằng cách chỉ dựa trên
thông tin của K điểm dữ liệu trong training set gần nó nhất (K-lân cận), khơng quan tâm đến việc có một
vài điểm dữ liệu trong những điểm gần nhất này là nhiễu. Hình dưới đây là một ví dụ về KNN trong
classification với K = 1.
Hình 3 KNN trong Classification với K=1
b. Learning Vector Quantization (LVQ)
11
Học lượng tử hóa Vector (Learning Vector Quantization - LVQ) là một thuật toán mà là một loại mạng
thần kinh nhân tạo và sử dụng tính thần kinh. Nói rộng hơn, nó có thể được cho là một loại trí thơng minh
tính tốn. Thuật tốn LVQ cho phép một để chọn số lượng đào tạo các trường hợp phải trải qua và sau đó
tìm hiểu về những gì, những trường hợp như thế nào. LVQ được phát minh bởi Teuvo Kohonen và có liên
quan đến thuật tốn KNN.
2.2.4. Clustering Algorithms
a. K-Means clustering
Trong thuật tốn K-means clustering, chúng ta khơng biết nhãn (label) của từng điểm dữ liệu. Mục đích là
làm thế nào để phân dữ liệu thành các cụm (cluster) khác nhau sao cho dữ liệu trong cùng một cụm có
tính chất giống nhau.
Mục đích cuối cùng của thuật tốn này là: từ dữ liệu đầu vào và số lượng nhóm chúng ta muốn tìm, chỉ ra
được center của mỗi nhóm và phân các điểm dữ liệu vào các nhóm tương ứng.
Có một vài hạn chế của thuật tốn K-means clustering:
Cần biết số lượng cluster cần clustering. Trong thực tế, nhiều trường hợp khơng xác định được giá trị này.
Có một số phương pháp giúp xác định số lượng clusters chẳng hạn như Elbow method.
Nghiệm cuối cùng phụ thuộc vào các centers được khởi tạo ban đầu. Tùy vào các center ban đầu mà thuật
tốn có thể có tốc độ hội tụ rất chậm hoặc thậm chí cho chúng ta nghiệm khơng chính xác (chỉ là local
minimum - điểm cực tiểu - mà không phải giá trị nhỏ nhất).
Các cluster cần có só lượng điểm gần bằng nhau
Các cluster cần có dạng hình trịn: Tức là các cluster tn theo phân phối chuẩn và ma trận hiệp phương
sai là ma trận đường chéo có các điểm trên đường chéo giống nhau.
Khi một cluster nằm phía trong 1 cluster khác. Ví dụ kinh điển về việc K-means clustering không thể
phân cụm dữ liệu. Một cách tự nhiên, chúng ta sẽ phân ra thành 4 cụm: mắt trái, mắt phải, miệng, xunh
quanh mặt. Nhưng vì mắt và miệng nằm trong khn mặt nên K-means clustering khơng thực hiện được.
Mặc dù có những hạn chế, K-means clustering vẫn cực kỳ quan trọng trong Machine Learning và là nền
tảng cho nhiều thuật toán phức tạp khác sau này.
b. K-Medians
K-Medians clustering là một thuật toán phân tích cụm. Nó là một biến thể của phân cụm k -means trong
đó thay vì tính giá trị trung bình cho mỗi cụm để xác định trọng tâm của nó thì nó sẽ tính tốn trung vị.
Điều này có tác dụng giảm thiểu lỗi trên tất cả các cụm liên quan đến chỉ số khoảng cách 1 chuẩn, trái
ngược với chỉ số khoảng cách 2 chuẩn bình phương (trái ngược với k -mean).
Hàm tiêu chí được xây dựng theo cách này đơi khi là một tiêu chí tốt hơn được sử dụng trong thuật toán
phân cụm k -means, trong đó tổng các khoảng cách bình phương được sử dụng. Tổng khoảng cách được
sử dụng rộng rãi trong các ứng dụng như vị trí cơ sở.
12
Thuật toán được đề xuất sử dụng phép lặp kiểu Lloyd xen kẽ giữa bước kỳ vọng (E) và bước tối đa hóa
(M), khiến đây trở thành thuật tốn tối đa hóa kỳ vọng. Trong bước E, tất cả các đối tượng được gán cho
trung vị gần nhất của chúng. Trong bước M, các trung bình được tính tốn lại bằng cách sử dụng trung vị
trong mỗi chiều đơn lẻ.
2.2.5 Artificial Neural Network Algorithms
a. Perceptron
Perceptron là một thuật toán Classification cho trường hợp đơn giản nhất : chỉ có hai class (lớp) (bài toán
với chỉ hai class được gọi là binary classification) và cũng chỉ hoạt động được trong một trường hợp rất
cụ thể. Tuy nhiên, nó là nền tảng cho một mảng lớn quan trọng của Machine Learning là Neural Networks
– mạng dây thần kinh và sau này là Deep Learning.
PLA có thể cho vơ số nghiệm khác nhau
PLA đòi hỏi dữ liệu linearly separable
b. Softmax Regression
Softmax Regression là một trong hai classifiers phổ biến nhất. Softmax Regression cùng
với SVM là hai classifier phổ biến nhất được dùng hiện nay. Softmax Regression đặc biệt được
sử dụng nhiều trong các mạng Neural có nhiều lớp (Deep Neural Networks hay DNN). Những
lớp phía trước có thể được coi như một bộ Feature Extractor, lớp cuối cùng của DNN cho bài
toán classification thường là Softmax Regression.
Hình 4 Softmax Regression dưới dạng mạng nơ ron
c. Multi-layer Perceptron
13
Mạng MLP (Multi-layer Perceptron) là à tập hợp của các perceptron chia làm nhiều nhóm, mỗi nhóm
tương ứng với một layer.
Trong mạng MLP ngoài hai lớp input layer và output layer các lớp khác được gọi chung là hidden layer.
Hình 5 Multi-layer Perceptron
2.2.6. Dimensionality Reduction Algorithm
a. Principal Component Analysis (PCA)
Phân tích thành phần chính (Principal Component Analysis – PCA) dựa trên quan sát rằng dữ liệu thường
không phân bố ngẫu nhiên trong không gian mà thường phân bố gần các đường/mặt đặc biệt nào đó. PCA
xem xét một trường hợp đặc biệt khi các mặt đặc biệt đó có dạng tuyến tính là các khơng gian con
(subspace).
PCA chính là phương pháp đi tìm một hệ cơ sở mới sao cho thông tin của dữ liệu chủ yếu tập trung ở một
vài toạ độ, phần còn lại chỉ mang một lượng nhỏ thơng tin. Và để cho đơn giản trong tính tốn, PCA sẽ
tìm một hệ trực chuẩn để làm cơ sở mới.
PCA là một phương pháp Unsupervised. Việc thực hiện PCA trên tồn bộ dữ liệu khơng phụ thuộc vào
class (nếu có) của mỗi dữ liệu. Việc này đơi khi khiến cho PCA không mang lại hiệu quả cho các bài tốn
classification.
Với các bài tốn Large-scale, đơi khi việc tính tốn trên tồn bộ dữ liệu là bất khả thi vì cịn có vấn đề về
bộ nhớ. Giải pháp là thực hiện PCA lần đầu trên một tập con dữ liệu vừa với bộ nhớ, sau đó lấy một tập
con khác để (incrementally) cập nhật nghiệm của PCA tới khi nào hội tụ được gọi là Incremental PCA.
Ngồi ra, cịn có thể mở rộng PCA ra rất nhiều hướng như: Sparse PCA, Kernel PCA, Robust PCA.
14
b. Linear Discriminant Analysis (LDA)
Linear Discriminant Analysis (LDA) được ra đời nhằm giải quyết vấn đề mà PCA không khắc phục được.
LDA là một phương pháp giảm chiều dữ liệu cho bài tốn classification. LDA cũng có thể được coi là
một phương pháp phân lớp (classification), và cũng có thể được áp dụng đồng thời cho cả hai, tức giảm
chiều dữ liệu sao cho việc phân lớp hiệu quả nhất. Số chiều của dữ liệu mới là nhỏ hơn hoặc bằng C − 1
trong đó C là số lượng classes. Từ ‘Discriminant’ được hiểu là những thông tin đặc trưng cho mỗi class,
khiến nó khơng bị lẫn với các classes khác. Từ ‘Linear’ được dùng vì cách giảm chiều dữ liệu được thực
hiện bởi một ma trận chiếu (projection matrix), là một phép biến đổi tuyến tính (linear transform).
Ý tưởng cơ bản của LDA là tìm một khơng gian mới với số chiều nhỏ hơn không gian ban đầu sao cho
hình chiếu của các điểm trong cùng 1 class lên khơng gian mới này là gần nhau trong khi hình chiếu của
các điểm của các classes khác nhau là khác nhau.
Trong PCA, số chiều của khơng gian mới có thể là bất kỳ số nào không lớn hơn số chiều và số điểm của
dữ liệu. Trong LDA, với bài toán có C classes, số chiều của khơng gian mới chỉ có thể khơng vượt q
C−1.
LDA có giả sử ngầm rằng dữ liệu của các classes đều tuân theo phân phối chuẩn và các ma trận hiệp
phương sai của các classes là gần nhau.
Với bài tốn có 2 classes, hai classes đó là linearly separable nếu và chỉ nếu tồn tại một đường thẳng và 1
điểm trên đường thẳng đó sao cho : dữ liệu hình chiếu trên đường thẳng của hai classes nằm về hai phía
khác nhau của điểm đó.
LDA hoạt động rất tốt nếu các classes là linearly separable, tuy nhiên, chất lượng mơ hình giảm đi rõ rệt
nếu các classes là không linearly separable. Điều này dễ hiểu vì khi đó, chiếu dữ liệu lên phương nào thì
cũng bị chồng lần, và việc tách biệt không thể thực hiện được như ở khơng gian ban đầu.
Ngồi những thuật tốn trên cịn có rất nhiều thuật tốn khác nữa.
III. Bài toán nhận dạng tiền mặt
1. Keras
Keras là một thư viện mã nguồn mở cung cấp giao diện python cho các mạng nơ rơn nhân tạo (artificial
neural networks). Keras là phần "high-level" với phần "low-level" có thể là tensorFlow, CNTK hoặc
Theano. Keras chứa nhiều triển khai các khối xây dựng mạng nơ-ron thường được sử dụng như lớp
(layers), mục tiêu (objective), chức năng kích hoạt (activation functions), trình tối ưu hóa (optimizers) và
một loạt các cơng cụ giúp làm việc với dữ liệu hình ảnh và văn bản dễ dàng hơn nhằm đơn giản hóa mã
cần thiết để viết mã mạng nơ-ron sâu (deep neural network).
Ngoài mạng lưới thần kinh chuẩn (standard neural networks), Keras còn hỗ trợ mạng thần kinh tích chập
(Convolutional Neutral Network) và mạng thần kinh tái phát (recurrent neural network).
15
Hình 6 Deep Learning Framwork Power Scores 2018
2. Convolutional Neutral Network (CNN)
Convolutional Neural Network (CNN hoặc ConvNet) hay còn gọi là mạng nơ rơn tích
chập. Đây là một trong những mơ hình tiên tiến của Deep Learning. CNN thường được áp dụng
phổ biến nhất trong phân tích xử lý hình ảnh trực quan.
CNN đã được đưa vào các nền tảng Facebook, Google, … để xử lý hình ảnh như nhận
diện khn mặt người dùng, nhận dạng hình ảnh, xe tự lái hay drone giao hàng tự động, …
CNN rất phù hợp và tối ưu cho xử lý phân loại hình ảnh vì vậy nhóm em quyết định sử
dụng CNN cho đồ án của mình.
Cấu trúc của CNN
16
Hình 7 Cấu trúc CNN
-
Convolution Layer (Conv Layer) là lớp đầu tiên để trích xuất các đặc trưng từ hình ảnh đầu vào.
Nó duy trì mối quan hệ giữa các pixel bằng cách tìm hiểu các đặc trưng hình ảnh với các ô vuông
nhỏ của dữ liệu đầu vào. Convolution Layer có nhiệm vụ thực hiện mọi tính tốn. Những yếu tố
quan trọng của một Convolution Layer là : filter map, stride, padding và feature map.
CNN sử dụng các filter để áp dụng vào các vùng của hình ảnh gọi là filter map. Những
filter map này là ma trận 3 chiều với những con số bên trong nó gọi là parameter.
+
Stride : khi dịch chuyển các filter map theo pixel dựa vào giá trị từ trái sang phải thì sự
dịch chuyển này được gọi là stride.
Hình 8 Convolve with 3x3 filter and stride is 2
+
Padding: là các giá trị 0 được thêm vào lớp input. Khi muốn các pixel ở viền của ảnh tiếp
xúc và tương tác nhiều hơn với bộ lọc có thể thêm những pixel có giá trị 0 vào viền của
hình ảnh mà khơng ảnh hưởng đến đầu vào khi bộ lọc được áp dụng.
17
Hình 9 Input 32x32x3 với padding=2
+
Feature map : Thể hiện kết quả của mỗi lần filter map quét qua input.
Hình 10 Minh họa feature map
-
ReLU Layer: áp dụng hàm kích hoạt g thường là max (0, x) lên đầu ra của Conv Layer. Mục đích
của nó là tăng tính phi tuyến tính cho mạng. ReLu Layer khơng làm thay đổi kích thước của ảnh
và khơng thêm bất kì tham số nào.
18
Hình 11 Hàm ReLu và các biến thể
-
Pooling Layer : khi đầu vào quá lớn pooling layer sẽ được xếp vào giữa các conv layer để làm
giảm số chiều không gian của đầu vào và giảm độ phức tạp của tính tốn.
Có hai loại pooling chủ yếu là max pooling và average pooling
Trong đó max pooling được sử dụng phổ biến hơn cả với ý tưởng: Giữ lại những chi tiết
quan trọng hay là giữ lại pixel có giá trị lớn nhất.
Hình 12 Max pooling và Average pooling
Tại Pooling Layer, khi sử dụng lớp Max Pooling thì số lượng Parameter có thể sẽ giảm
đi. Vì vậy, Convolutional Neural Network sẽ xuất hiện nhiều lớp Filter Map, mỗi Filter Map đó
sẽ cho ra một Max Pooling khác nhau.
19
-
Fully Connected Layer là các lớp kết nối đầy đủ như các mạng NN thông thường. Sau khi ảnh
được đưa qua các lớp Conv Layer và Pooling Layer thì model đã học được tương đối các đặc
điểm của ảnh, các output của layer cuối sẽ được dàn phẳng (Flattening) ra thành vector và đưa
vào Fully Connected Layer. Cuối cùng sử dụng hàm softmax hoặc hàm sigmoid để phân loại đầu
ra. Với bài tốn phân loại (classification) thì nếu có 2 output thì hàm activation ở output layer sẽ
là hàm sigmoid, nếu có nhiều hơn 2 output thì hàm activation ở output layer sẽ là hàm softmax.
Hình 13 Minh họa Fully Connected Layer
20
Hình 14 Minh họa hàm Softmax
3. VGG16
VGG16 là mạng convolutional neural network được đề xuất bởi K. Simonyan and A.
Zisserman, University of Oxford. Model sau khi train bởi mạng VGG16 đạt độ chính xác 92.7%
top-5 test trong dữ liệu ImageNet gồm 14 triệu hình ảnh thuộc 1000 lớp khác nhau.
Hình 15 Cấu trúc mạng VGG16
-
Convolutional layer: kích thước 3*3, padding=1, stride=1.
Pool/2: max pooling layer với size 2*2.
Càng về sau thì kích thước của input càng giảm nhưng trọng số ngày càng tăng (64 -> 128 ->
256->512 ->4096).
21
-
Sau nhiều Conv Layer và Pooling Layer thì dữ liệu sẽ được dàn phẳng (flattening) và đưa vào
Fully Connected Layer.
4. Transfer Learning
Transfer Learning là một kỹ thuật mà trong đó một pretrained model đã được train trên
source tasks cụ thể nào đó, khi đó một phần hay tồn bộ pretrained model có thể được tái sử
dụng phụ thuộc vào nhiệm vụ của mỗi layer trong model đó. Một model mới sử dụng một phần
hay toàn bộ pretrained model để học một target tasks và tùy vào nhiệm vụ của mỗi layer mà
model mới có thể thêm các layer khác dựa trên pretrained model sẵn có.
5. Các bước thực hiện chính của bài toán nhận diện tiền mặt
-
Tạo dữ liệu bằng cách đọc ảnh các tờ tiền từ camera
Thiết kế mạng NN với đầu vào là ảnh (128,128,3), đưa vào mạng VGG16 và đầu ra của VGG16
sẽ dùng để đưa vào 1 mạng NN nhỏ kết thúc bằng 1 lớp Dense và hàm softmax.
Đầu ra sẽ là 1 vector softmax chứa các probality p(i) ứng với mỗi class i, chúng ta sẽ in ra giá trị
max trong vector đó và chọn đó làm class dự đốn.
Đầu tiên trước khi bước vào q trình huấn luyện (training) dữ liệu cần phải có dữ liệu
cho bài tốn. Về tiền Việt Nam thì khơng có sẵn bộ dữ liệu nào trên mạng nên phải tự tạo dữ liệu
bằng cách đọc liên tục từ camera và lưu lại vào thư mục tương ứng với các mệnh giá tiền. Ở đây
nhóm em sử dụng 3 tờ tiền là 10000, 20000 và 50000 VNĐ và một nhãn 00000 dành cho ảnh
khơng có xuất hiện tiền. Lần lượt chạy đoạn code sau với các tên thư mục tương ứng với mệnh
giá tờ tiền đang chọn làm dữ liệu :
22
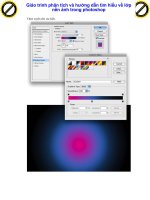
Hình 16 Tạo dữ liệu
Sau khi chạy xong cho 4 loại tiền thì các dữ liệu hình ảnh đầu vào của 4 loại tiền được
lưu vào thư mục data với các thư mục con có tên tương ứng với các mệnh giá tiền.
Hình 17 Dữ liệu để training
23
Hình 18 Ảnh minh họa dữ liệu
Đọc cái hình ảnh trong các thư mục đã tạo và resize các hình ảnh trong bộ dữ liệu thành
kích thước (128,128)
Sau đó convert các nhãn (00000,10000,20000,50000) thành one-hot sử dụng class
LabelBinarizer trong thư viên sklearn và lưu vào file pix.data để load dữ liệu cho lần sau.
Tiếp theo là training model. Chúng em tận dụng phần trích xuất đặc trưng của VGG16
24
Hình 19 Cấu trúc VGG16
Bỏ đi phần Classifier của mạng VGG16 và dùng phần còn lại làm input cho lớp Fully
Connected của mình
Đầu tiên chia dữ liệu thành tập train và tập test với tỉ lệ là tập train 80% cịn tập test là
20%
Hình 20 Chia train:test tỉ lệ 8:2
Lượt bỏ phần Classifier của mạng VGG16
Ở đây, chúng em chỉ điều chỉnh phần weights của phần Fully Connected thêm vào nên
chúng em sẽ đóng băng các layer của VGG vì VGG đã được train rất tốt rồi. Phần Fully
connected mới bao gồm một lớp dàn phẳng input (flattening), 2 lớp Dense với hàm kích hoạt
reLu, sử dụng Dropout để bỏ qua những nút trong mạng một cách ngẫu nhiên nhầm giảm thiểu
over-fitting. Cuối cùng là một lớp Dense (4) với hàm kích hoạt softmax để phân loại dữ liệu
thành 4 output.
25