Adobe Dreamweaver CS3 Unleashed- P21 doc
Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây (631.01 KB, 50 trang )
If you look at the Vecta Corp store example again, you can begin to imagine how the DBMS looks much like
the filing cabinet discussed earlier. Unlike a filing cabinet, however, which typically contains two to four
drawers, a DBMS can manage hundreds, possibly thousands of databases—all of which are immediately at
your fingertips. Later in this chapter, we'll look at the various database management systems that exist on
the market today for interacting with SQL Server 2005 Express Edition and MySQL, including the File
Manager for Access.
The Database
Inside your DBMS, you have the potential for storing hundreds, if not thousands, of databases. Although for
most projects you would never need more than one database, you may in the future realize that your
project has grown far beyond the scope of a single database—that because of security or maintenance
reasons, you require more. Figure 22.3 shows MySQL Administrator with a list of three catalogs (otherwise
known as databases) housed within its framework.
Figure 22.3. MySQL Administrator and a list of the databases it contains.
[View full size image]
Tables
After a database has been created, you might want to begin storing information relevant to a specific part of
the store. As mentioned earlier, tables are very similar to file cabinet drawers. It would be a mistake to
store all the information about inventory, product information, customers, and even transactions in one
drawer; instead, you'll break out these categories of information and create different drawers or tables to
store all this information.
Figure 22.4 shows the Vecta Corp store database in MySQL Administrator. By selecting the Vecta Corp store
database from the view in the left column, you can begin to see all the tables that reside within the store.
Figure 22.4. Selecting the vectacorp database reveals all the tables associated with the project.
[View full size image]
Notice that there are more tables than just the four outlined in the beginning of the chapter. If you think in
terms of space and redundancy, you will see exactly why you need to include more than just a few tables.
As far as the Employees table is concerned, you could have a customer that has multiple credit cards on
file—hence the need for a separate CreditCards table. You will also have customers/employees who belong
to a specific department—hence the need for a separate Departments table. We could even go beyond this
example and create a separate table for CreditCardTypes, assuming a customer could use more than one
credit card. This process of organizing data in an effort to avoid data duplication within tables is known as
normalization and is discussed in depth toward the end of this chapter.
Note
In this example, customers represent employees of Vecta Corp. Remember, we're building an
internal web store for Vecta Corp employees. Because this is the case, Vecta Corp customers are
employees. For this reason, the database table has been named Employees instead of Customers.
Before you begin any project, you will typically sketch all this out in an effort to reduce data duplication in
your tables. Again, how you branch out your information and create tables depends on how big in scope
your project is.
Columns
After you outline all your tables, your next step is to decide what information to include within those tables.
For instance, you might want to include first name, last name, phone number, address, city, state, ZIP, and
so on for all the employees in your company in the Employees table. You might also need to include product
names, descriptions, and some sort of unique identification in your EmployeeStore table. You might even
want to combine certain aspects of certain tables and place them into the Orders table—for example, you
might end up with information from the Employees table as well as from the EmployeeStore table to come
up with a final order requisition.
Theoretically, columns represent bits of information or more detailed descriptions of the table in which they
are contained. Just as you have an Employees table, all employees must have names and physical
addresses. Just as you have an EmployeeStore table, all products must have names and descriptions. Figure
22.5 shows what the Employees table might look like after columns have been outlined.
Figure 22.5. The Employees table displays all the columns associated with it.
[View full size image]
Rows
Think back to the example I mentioned earlier regarding the documents within the folders and the folders
within the drawers contained within the filing cabinet. Rows represent the actual data in those documents.
Similar to the columns within the tables, rows represent the actual data within the columns. When
employees/customers begin purchasing items, the rows in the Orders table begin to expand and fill up with
information, similar to Figure 22.6.
Figure 22.6. The Orders table with multiple rows of information.
[View full size image]
Database tables have the potential for containing millions of rows. Technically, this is your data. The many
rows of information contained in your database tables are what you'll ultimately display in your web
applications. Whether you're displaying product information for employees to select, order information for
the shipping and receiving department to review, or employee information for administrators to configure,
the rows in your databases tables and the data contained within those rows are what you'll ultimately be
interacting with inside the web application.
Beyond the Basics
Now that we've gotten the basic structure of a database out of the way, let's begin thinking about what
really drives the database. Aside from the data in the tables, other characteristics and functions of the
database can improve performance, reduce network traffic, increase security, decrease development time,
and dramatically decrease maintenance efforts. Some of these functions and characteristics are listed next:
Stored procedures
Triggers
Views and queries
Security
Relationship management
Keys
Normalization
It's important to understand that these concepts are not relevant to all databases. For instance, concepts
such as stored procedures, triggers, views, security management, relationship management, and keys are
all relevant to SQL Server. Access, being the proverbial little brother of SQL Server, supports only queries,
security management, relationships, and keys. In contrast, MySQL is somewhat limited when it comes to
these concepts. For instance, the latest recommended release of MySQL supports only a handful of these
topics.
Stored Procedures
Stored procedures are a way of actually storing code that you use to work with your database in the
database itself. They are a way of modularizing repetitive code so that you never have to write the same
line of code in your applications more than once. You create a stored procedure within your database and
call it through your application, passing in parameters as necessary. In return, the stored procedure
executes complex tasks and can return information back to the application that is calling it.
Let's use the Vecta Corp store as an example. In our application, we might want to create two ways of
updating registered users within our database. From a user's standpoint, the customer might want to edit
existing passwords, personal information, or perhaps shipping information. From an administrative
standpoint, the admin might also want the capability to update a given user's information. Although the
front-end user interface will look completely different for the users and administrator, the code that
accesses the database and performs the actual data modification can be the same. This concept is outlined
visually in Figure 22.7.
Figure 22.7. Stored procedures allow you to consolidate repetitive functionality by modularizing
it into a single function residing on the database server rather than the web server.
[View full size image]
By creating a stored procedure, we would essentially eliminate the arduous task of writing repetitive code
for both user and administrator instances. We write it once as a stored procedure and allow the user and
administrator to access the stored procedure the same way.
Triggers
Triggers, which are similar to stored procedures, can be set up to run with your database data. Triggers are
predefined events that run automatically whenever a specified action (preferably Insert, Delete, or Update
command) is performed on a physical file. Although it might sound a bit confusing as to what triggers
actually are and what they can do, think of triggers as a way of enforcing business rules you may have
described within your database. Triggers enforce stability and integrity within your tables.
For example, in the Vecta Corp database you'll have a table for employee orders, called Orders. If the
employee ended a relationship with the Vecta Corp store, you would have the potential for orders in the
Orders table that are not associated with any employee. Triggers would enforce business rules by making
sure that if an employee ended a relationship with Vecta Corp (maybe they quit or were fired), not only is
their information in the Employees table deleted, but the data in the Orders table (which had a direct
relationship with data in the Employees table) would be deleted as well.
Views and Queries
Views (SQL Server/MySQL) and queries (Access) are awkward to think about at first because their names
are deceiving. Views and queries aren't actually what their names imply; rather, they are virtual tables
whose contents are defined by a query. Much like a real table with rows and columns, views and queries
exist as stored sets of data values. Rows and columns of data come from the tables that are referenced and
are produced dynamically by the database when the view or query is called from the application.
For example, you could have multiple databases set up throughout your company—one for sales, one for
marketing, and possibly one for operations. You could use views and queries to combine similar data from
all those databases to produce a virtual table with sales numbers, marketing reports, and even information
from operations. After the query/view has been created, the information is easily accessible by your web
application. We'll cover views and queries at a basic level in the next chapter.
Security
Security is always important to any facet of development, not just web development. Ensuring that your
database is secure and accessible only by certain individuals or departments is crucial. Many database
management systems provide a way to set security options for users and groups of users who are allowed
to access the database either individually or within their own web applications. Figure 22.8 shows how you
could modify permissions (select the User Information category and specify details for a new user account)
for specific users using MySQL Administrator.
Figure 22.8. User administration is easy using MySQL Administrator.
[View full size image]
Access, on the other hand, enables you to modify security settings by right-clicking the database file,
selecting Properties, and choosing the Security tab, as shown in Figure 22.9.
Figure 22.9. Adding users and permissions to an Access database file.
Access itself allows you to control permissions for a particular database file. You can modify permissions for
a database file by first opening the database file. Next, select Tools, Security, and User and Group
Permissions. The User and Group Permissions dialog allows you to specify which users get Read and Modify
permissions or no permissions at all. You can even modify or set permissions for specific tables, queries,
forms, and reports.
Relationship Management
When you create new tables in your database, an important aspect to consider is that of relationships. We
have already touched on what relationships are and how they relate to your tables. For example, you could
create a separate table for credit cards and assign that table a relationship with the Employees table. The
reason for doing this is simple: It allows you to store more than one credit card for a particular employee. In
this scenario, we'd create a separate table for credit cards and assign each row in that column a unique
identifier, usually an automatically generated number. The relationship would exist between the unique
identifier in the Employees table (CustomerID) and that identifier in the CreditCards table. Figure 22.10
shows a relationship between the Employees table and the CreditCards table using Access's relationship
modeler.
Figure 22.10. Relationships are added to avoid data duplication in tables.
[View full size image]
In general, when you work with relationship modeling, three types of relationships exist:
One-to-one— A one-to-one relationship means that for each record that exists in one table, only one
other related record can exist in another table. One-to-one relationships are rarely used, and when
they are, it's usually because of a limitation with the database that requires data to be stored
separately—usually because of the database's size.
One-to-many— A one-to-many relationship is by far the most common of relationship types. A one-
to-many relationship means that for each record in one table, multiple records can exist in a second
table. These records are usually related based on a unique number (a primary key). In the
employees/credit cards example I mentioned earlier, a one-to-many relationship created a relationship
between one customer and the many possible credit card numbers that could be stored in a second
(credit cards) table.
Many-to-many— A many-to-many relationship exists when many records in one table are related to
many records in a second table. Many-to-many relationships are difficult to illustrate in a typical
relational database model and are not often used in practice.
Keys
Many of the records in your database will contain information that is very similar in nature. You might have
a thousand customers in your Employees table, and a hundred of those customers might be from San Diego.
If you extracted all those records from the database, how would you be able to differentiate among all the
records? Obviously you could differentiate by name, but what if you had three records in the database with
the name John Smith from San Diego? A way to differentiate is through the use of unique keys.
Think about why uniqueness is so important. If you had more than one record in the database that was the
same, what would be the sense in storing multiple copies? It would be a waste of space. Also, if you tried to
update or delete a record from a database that matched a second record, the database would not be able to
match the record you were trying to work with, and you might end up deleting the wrong record, throwing
an error, or corrupting the data in your tables. Records can be identified through the use of three kinds of
keys:
Candidate keys— A candidate key is a set of columns that are unique across the board. Take the
following example:
ZIP
Area
92069
San Marcos
92115
San Diego
92105
San Diego
92128
San Diego
In this example, the ZIP column could be considered a candidate key because the values never repeat.
Although the Area names do repeat, together with the ZIP value, they become unique and can make
up a candidate key. Because the Area column contains repetitive information, it cannot be considered
for a candidate key and could never be unique.
Primary keys— Whereas candidate keys can be made up of several columns, a primary key (PK) is
usually made up of a single column that designates a row in the table as unique. For the most part,
primary keys can exist even though they have no relationship to the data being stored. Database
developers often create primary keys with an automatically generated number, guaranteeing that the
row always increments by 1 and remains unique from any other records. Primary keys are the most
useful when referenced from a second table through the use of foreign keys. The table that follows
illustrates a simple table within a database that contains information about a user's area. Because the
primary key is different, the records remain completely unique even though data within the Area
column repeats.
AreaPK
Area
1
San Marcos
2
San Diego
3
San Diego
4
San Diego
Foreign keys— A foreign key (FK) is a column that contains values found in the primary key of
another table. A foreign key can be null and almost always is not unique. Consider the following
example:
ZipPK
ZipCode
1
92069
2
92115
3
92105
4
92128
AreaPK
AreaName
ZipFK
1
San Diego
3
2
San Diego
2
3
Tijuana
—
4
San Marcos
1
5
San Marcos
1
6
San Diego
4
7
San Diego
4
The ZipFK column in the second table is a foreign key to the ZipPK primary key in the first table. Notice that
the ZipPK values are unique and not null, but the ZipFK values might be null and often repeat. A null foreign
key means that row does not participate in the relationship. In a one-to-many relationship, the primary key
has the "one" value, and the foreign key has the "many" values.
Normalization
As discussed earlier in the chapter, normalization is the process of organizing data in an effort to avoid
duplication. Often this process involves separating data into discrete related tables. Advantages to
normalization usually include space, performance, and easier maintenance.
Typically, normalization involves the process of identifying all the data objects that should be in your
database, all their relationships, and defining the tables required and the columns within each table.
Consider how the EmployeeStore table would look if we did not normalize the data into separate tables:
Customer
Order
Price
Zak
Shirt
$12
Patty
Shirt
$12
Zak
Pants
$35
Mackenzie
Shoes
$75
Jessica
Blouse
$20
Judy
Shoes
$75
Jessica
Blouse
$20
If the preceding table was used specifically to keep track of the price of items and you wanted to delete a
price, you would end up deleting an employee as well. Instead, you could separate the employees into their
own table and the products along with their prices into a second table. If a specific employee orders a
product, the product and its price are placed into a third Orders table along with the corresponding customer
data referenced by a one-to-many relationship.
For the most part, normalization isn't a feature of the database; rather, it's a practice you should follow. On
that point, there are roughly four normalization forms that define how data is laid out within a database:
The First Normal Form— The first normal form states that all rows in a table must contain different
data. No duplicate rows are permitted. It also states that all entries in a specific column must be of the
same type—for instance, a column named Customer must contain only names of customers.
The Second Normal Form— The second normal form states that no field can be inherited from
another field. For example, if you store the full name of a customer in the Employees table, you cannot
create a second field to store only the last name of a customer, because the data would be redundant.
The Third Normal Form— The third normal form states that duplicate information is not allowed in
the database. This is the model you achieved in the foreign key example. Instead of storing the credit
cards of a customer within the Customers table, you separate that information out into a second table,
allowing for multiple credit cards to be entered.
Domain/Key Normal Form— A domain/key normal form states that a key uniquely identifies each
row in a table. By enforcing key restrictions, the database is freed of modification irregularities.
Domain/key normal form is the normalization form that most database developers try to achieve.
Chapter 22. A Database Primer
IN THIS CHAPTER
Anatomy of a Database
Installing a Database
Installing SQL Server 2005 Express Edition
Installing MySQL
An Overview of the Vecta Corp Database
As you begin to build dynamic web applications using Dreamweaver, it will become increasingly obvious that
you'll need to store data in some sort of storage mechanism and allow access to it through your web
application. Whether you are building a small, companywide Intranet store with access limited to employees
or a feature-rich Internet web store that millions will visit, you will need some system for storing all the
order, customer, cost, and product information. You might not want to stop there. You might also want to
include some way of tracking how many of a certain item you have left in your inventory. You might even
need to determine how many items are selling during a particular week of the month. If that's the case, you
will need some way of determining sales transactions. Like a filing cabinet that stores files and,
subsequently, data within those files, you will need some mechanism of storing all your data for easy access
and quick retrieval. That mechanism is the database.
In this chapter, we'll demystify databases. We'll cover basic database concepts such as tables, columns, and
rows, as well as advanced concepts such as stored procedures, views and queries, security, relationships,
and keys. Then we'll talk about the three databases covered in this book: Access, SQL Server 2005 Express
Edition, and MySQL. We'll dissect their installation and configuration and provide an overview of the
database management systems utilized by each. Finally, we'll provide a high-level overview of the Vecta
Corp database and its tables.
As you've done for the rest of the chapters in this book, you can work with the examples in this chapter by
downloading the files from www.dreamweaverunleashed.com. As you'll see throughout the chapter, the
downloadable files include complete versions of the databases used in this chapter.
Anatomy of a Database
In 1970, E. F. Codd, an IBM employee, proposed his idea for what would become the first relational
database design model. His model, which proposed new methods for storing and retrieving data in large
applications, far surpassed any idea or system that was in place at that time. His idea of "relational"
stemmed from the fact that data and relationships between them were organized in "relations," or what we
know today as tables. Even though Codd's terminology of what we refer to as tables, columns, and rows was
different, the premise behind the relational model has remained consistent. Although the model has
undergone revisions and changes since he presented it, the idea of storing and retrieving information in
large applications has not changed, solidifying the need for the relational database model.
The best way to think of a database is in terms of a filing cabinet. The filing cabinet contains drawers, the
drawers contain folders, and the folders contain documents that have information on them. A database is
similar in concept. A database contains drawers, otherwise known as tables; those tables contain folders, or
columns, which in turn contain rows of information pertaining to the particular column that they're in.
For a moment, let's take the web store example (crudely outlined in Chapter 20, "Introduction to Web
Applications") and break it down to see exactly what kind of information we would need and just how we
could organize it to make it manageable with a database.
Customers— We need some way of keeping track of all our registered customers, along with
shipping/billing addresses, credit card information, and so forth.
Products— We need some way of differentiating among all our products, including sizes, colors,
prices, quantities left in stock, and other characteristics that relate to a specific item.
Orders— Whenever a product is purchased from the online store, that order should be stored
somewhere in a queue of sorts so that the shipping and receiving department can process the order.
Transactions— We need to include a history of all transactions and a way of knowing which
customers are ordering what products so that we can recommend products to people dynamically in
the future.
Traditionally, we could take all these elements and create a Word document or perhaps a spreadsheet in
Excel and physically write on these documents whenever someone orders a product. We could take these
documents and store them in folders alphabetically and even store all the folders within one central filing
cabinet. Although this is a traditional example of how business can work, it closely resembles how the
modern database operates in relation. The filing cabinet—the drawers, folders, and even the documents
within them—all represent the basic components of a modern database structure:
Database management system
Database
Tables
Columns
Rows
Let's discuss each component in more detail.
The Database Management System (DBMS)
The database management system (DBMS) represents the framework from which you design, store, and
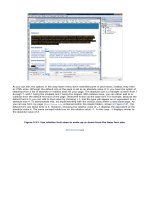
manage all the databases that you create. Figure 22.1 shows SQL Server 2005's Management Studio
Express. Management Studio Express is a centralized location for managing and interacting with all your
SQL Server databases.
Figure 22.1. Management Studio is an example of a database management system (DBMS) used
with SQL Server 2005 and SQL Server 2005 Express Edition.
[View full size image]
Although smaller databases such as Access do not have what is traditionally known as a DBMS, Access does
provide a way of interacting with and managing a single database file. Figure 22.2 shows how you can open
a database through Access.
Figure 22.2. Access does not provide a typical DBMS, but it does allow for access to any single
database file.
[View full size image]
If you look at the Vecta Corp store example again, you can begin to imagine how the DBMS looks much like
the filing cabinet discussed earlier. Unlike a filing cabinet, however, which typically contains two to four
drawers, a DBMS can manage hundreds, possibly thousands of databases—all of which are immediately at
your fingertips. Later in this chapter, we'll look at the various database management systems that exist on
the market today for interacting with SQL Server 2005 Express Edition and MySQL, including the File
Manager for Access.
The Database
Inside your DBMS, you have the potential for storing hundreds, if not thousands, of databases. Although for
most projects you would never need more than one database, you may in the future realize that your
project has grown far beyond the scope of a single database—that because of security or maintenance
reasons, you require more. Figure 22.3 shows MySQL Administrator with a list of three catalogs (otherwise
known as databases) housed within its framework.
Figure 22.3. MySQL Administrator and a list of the databases it contains.
[View full size image]
Tables
After a database has been created, you might want to begin storing information relevant to a specific part of
the store. As mentioned earlier, tables are very similar to file cabinet drawers. It would be a mistake to
store all the information about inventory, product information, customers, and even transactions in one
drawer; instead, you'll break out these categories of information and create different drawers or tables to
store all this information.
Figure 22.4 shows the Vecta Corp store database in MySQL Administrator. By selecting the Vecta Corp store
database from the view in the left column, you can begin to see all the tables that reside within the store.
Figure 22.4. Selecting the vectacorp database reveals all the tables associated with the project.
[View full size image]
Notice that there are more tables than just the four outlined in the beginning of the chapter. If you think in
terms of space and redundancy, you will see exactly why you need to include more than just a few tables.
As far as the Employees table is concerned, you could have a customer that has multiple credit cards on
file—hence the need for a separate CreditCards table. You will also have customers/employees who belong
to a specific department—hence the need for a separate Departments table. We could even go beyond this
example and create a separate table for CreditCardTypes, assuming a customer could use more than one
credit card. This process of organizing data in an effort to avoid data duplication within tables is known as
normalization and is discussed in depth toward the end of this chapter.
Note
In this example, customers represent employees of Vecta Corp. Remember, we're building an
internal web store for Vecta Corp employees. Because this is the case, Vecta Corp customers are
employees. For this reason, the database table has been named Employees instead of Customers.
Before you begin any project, you will typically sketch all this out in an effort to reduce data duplication in
your tables. Again, how you branch out your information and create tables depends on how big in scope
your project is.
Columns
After you outline all your tables, your next step is to decide what information to include within those tables.
For instance, you might want to include first name, last name, phone number, address, city, state, ZIP, and
so on for all the employees in your company in the Employees table. You might also need to include product
names, descriptions, and some sort of unique identification in your EmployeeStore table. You might even
want to combine certain aspects of certain tables and place them into the Orders table—for example, you
might end up with information from the Employees table as well as from the EmployeeStore table to come
up with a final order requisition.
Theoretically, columns represent bits of information or more detailed descriptions of the table in which they
are contained. Just as you have an Employees table, all employees must have names and physical
addresses. Just as you have an EmployeeStore table, all products must have names and descriptions. Figure
22.5 shows what the Employees table might look like after columns have been outlined.
Figure 22.5. The Employees table displays all the columns associated with it.
[View full size image]
Rows
Think back to the example I mentioned earlier regarding the documents within the folders and the folders
within the drawers contained within the filing cabinet. Rows represent the actual data in those documents.
Similar to the columns within the tables, rows represent the actual data within the columns. When
employees/customers begin purchasing items, the rows in the Orders table begin to expand and fill up with
information, similar to Figure 22.6.
Figure 22.6. The Orders table with multiple rows of information.
[View full size image]
Database tables have the potential for containing millions of rows. Technically, this is your data. The many
rows of information contained in your database tables are what you'll ultimately display in your web
applications. Whether you're displaying product information for employees to select, order information for
the shipping and receiving department to review, or employee information for administrators to configure,
the rows in your databases tables and the data contained within those rows are what you'll ultimately be
interacting with inside the web application.
Beyond the Basics
Now that we've gotten the basic structure of a database out of the way, let's begin thinking about what
really drives the database. Aside from the data in the tables, other characteristics and functions of the
database can improve performance, reduce network traffic, increase security, decrease development time,
and dramatically decrease maintenance efforts. Some of these functions and characteristics are listed next:
Stored procedures
Triggers
Views and queries
Security
Relationship management
Keys
Normalization
It's important to understand that these concepts are not relevant to all databases. For instance, concepts
such as stored procedures, triggers, views, security management, relationship management, and keys are
all relevant to SQL Server. Access, being the proverbial little brother of SQL Server, supports only queries,
security management, relationships, and keys. In contrast, MySQL is somewhat limited when it comes to
these concepts. For instance, the latest recommended release of MySQL supports only a handful of these
topics.
Stored Procedures
Stored procedures are a way of actually storing code that you use to work with your database in the
database itself. They are a way of modularizing repetitive code so that you never have to write the same
line of code in your applications more than once. You create a stored procedure within your database and
call it through your application, passing in parameters as necessary. In return, the stored procedure
executes complex tasks and can return information back to the application that is calling it.
Let's use the Vecta Corp store as an example. In our application, we might want to create two ways of
updating registered users within our database. From a user's standpoint, the customer might want to edit
existing passwords, personal information, or perhaps shipping information. From an administrative
standpoint, the admin might also want the capability to update a given user's information. Although the
front-end user interface will look completely different for the users and administrator, the code that
accesses the database and performs the actual data modification can be the same. This concept is outlined
visually in Figure 22.7.
Figure 22.7. Stored procedures allow you to consolidate repetitive functionality by modularizing
it into a single function residing on the database server rather than the web server.
[View full size image]
By creating a stored procedure, we would essentially eliminate the arduous task of writing repetitive code
for both user and administrator instances. We write it once as a stored procedure and allow the user and
administrator to access the stored procedure the same way.
Triggers
Triggers, which are similar to stored procedures, can be set up to run with your database data. Triggers are
predefined events that run automatically whenever a specified action (preferably Insert, Delete, or Update
command) is performed on a physical file. Although it might sound a bit confusing as to what triggers
actually are and what they can do, think of triggers as a way of enforcing business rules you may have
described within your database. Triggers enforce stability and integrity within your tables.
For example, in the Vecta Corp database you'll have a table for employee orders, called Orders. If the
employee ended a relationship with the Vecta Corp store, you would have the potential for orders in the
Orders table that are not associated with any employee. Triggers would enforce business rules by making
sure that if an employee ended a relationship with Vecta Corp (maybe they quit or were fired), not only is
their information in the Employees table deleted, but the data in the Orders table (which had a direct
relationship with data in the Employees table) would be deleted as well.
Views and Queries
Views (SQL Server/MySQL) and queries (Access) are awkward to think about at first because their names
are deceiving. Views and queries aren't actually what their names imply; rather, they are virtual tables
whose contents are defined by a query. Much like a real table with rows and columns, views and queries
exist as stored sets of data values. Rows and columns of data come from the tables that are referenced and
are produced dynamically by the database when the view or query is called from the application.
For example, you could have multiple databases set up throughout your company—one for sales, one for
marketing, and possibly one for operations. You could use views and queries to combine similar data from
all those databases to produce a virtual table with sales numbers, marketing reports, and even information
from operations. After the query/view has been created, the information is easily accessible by your web
application. We'll cover views and queries at a basic level in the next chapter.
Security
Security is always important to any facet of development, not just web development. Ensuring that your
database is secure and accessible only by certain individuals or departments is crucial. Many database
management systems provide a way to set security options for users and groups of users who are allowed
to access the database either individually or within their own web applications. Figure 22.8 shows how you
could modify permissions (select the User Information category and specify details for a new user account)
for specific users using MySQL Administrator.
Figure 22.8. User administration is easy using MySQL Administrator.
[View full size image]
Access, on the other hand, enables you to modify security settings by right-clicking the database file,
selecting Properties, and choosing the Security tab, as shown in Figure 22.9.
Figure 22.9. Adding users and permissions to an Access database file.
Access itself allows you to control permissions for a particular database file. You can modify permissions for
a database file by first opening the database file. Next, select Tools, Security, and User and Group
Permissions. The User and Group Permissions dialog allows you to specify which users get Read and Modify
permissions or no permissions at all. You can even modify or set permissions for specific tables, queries,
forms, and reports.
Relationship Management
When you create new tables in your database, an important aspect to consider is that of relationships. We
have already touched on what relationships are and how they relate to your tables. For example, you could
create a separate table for credit cards and assign that table a relationship with the Employees table. The
reason for doing this is simple: It allows you to store more than one credit card for a particular employee. In
this scenario, we'd create a separate table for credit cards and assign each row in that column a unique
identifier, usually an automatically generated number. The relationship would exist between the unique
identifier in the Employees table (CustomerID) and that identifier in the CreditCards table. Figure 22.10
shows a relationship between the Employees table and the CreditCards table using Access's relationship
modeler.
Figure 22.10. Relationships are added to avoid data duplication in tables.
[View full size image]
In general, when you work with relationship modeling, three types of relationships exist:
One-to-one— A one-to-one relationship means that for each record that exists in one table, only one
other related record can exist in another table. One-to-one relationships are rarely used, and when
they are, it's usually because of a limitation with the database that requires data to be stored
separately—usually because of the database's size.
One-to-many— A one-to-many relationship is by far the most common of relationship types. A one-
to-many relationship means that for each record in one table, multiple records can exist in a second
table. These records are usually related based on a unique number (a primary key). In the
employees/credit cards example I mentioned earlier, a one-to-many relationship created a relationship
between one customer and the many possible credit card numbers that could be stored in a second
(credit cards) table.
Many-to-many— A many-to-many relationship exists when many records in one table are related to
many records in a second table. Many-to-many relationships are difficult to illustrate in a typical
relational database model and are not often used in practice.
Keys
Many of the records in your database will contain information that is very similar in nature. You might have
a thousand customers in your Employees table, and a hundred of those customers might be from San Diego.
If you extracted all those records from the database, how would you be able to differentiate among all the
records? Obviously you could differentiate by name, but what if you had three records in the database with
the name John Smith from San Diego? A way to differentiate is through the use of unique keys.
Think about why uniqueness is so important. If you had more than one record in the database that was the
same, what would be the sense in storing multiple copies? It would be a waste of space. Also, if you tried to
update or delete a record from a database that matched a second record, the database would not be able to
match the record you were trying to work with, and you might end up deleting the wrong record, throwing
an error, or corrupting the data in your tables. Records can be identified through the use of three kinds of
keys:
Candidate keys— A candidate key is a set of columns that are unique across the board. Take the
following example:
ZIP
Area
92069
San Marcos
92115
San Diego
92105
San Diego
92128
San Diego
In this example, the ZIP column could be considered a candidate key because the values never repeat.
Although the Area names do repeat, together with the ZIP value, they become unique and can make
up a candidate key. Because the Area column contains repetitive information, it cannot be considered
for a candidate key and could never be unique.
Primary keys— Whereas candidate keys can be made up of several columns, a primary key (PK) is
usually made up of a single column that designates a row in the table as unique. For the most part,
primary keys can exist even though they have no relationship to the data being stored. Database
developers often create primary keys with an automatically generated number, guaranteeing that the
row always increments by 1 and remains unique from any other records. Primary keys are the most
useful when referenced from a second table through the use of foreign keys. The table that follows
illustrates a simple table within a database that contains information about a user's area. Because the
primary key is different, the records remain completely unique even though data within the Area
column repeats.
AreaPK
Area
1
San Marcos
2
San Diego
3
San Diego
4
San Diego
Foreign keys— A foreign key (FK) is a column that contains values found in the primary key of
another table. A foreign key can be null and almost always is not unique. Consider the following
example:
ZipPK
ZipCode
1
92069
2
92115
3
92105
4
92128