Tự động sinh mục lục cho văn bản
Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây (1.17 MB, 48 trang )
ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Nguyễn Việt Cường
TỰ ĐỘNG SINH MỤC LỤC
CHO VĂN BẢN
Ngành: Công nghệ thông tin
Chuyên ngành: Hệ thống thông tin
Mã số: 60 48 05
LUẬN VĂN THẠC SĨ
NGƯỜI HƯỚNG DẪN KHOA HỌC
PGS.TS. HÀ QUANG THUỴ
HÀ NỘI – 2007
iii
MỤC LỤC
LỜI CẢM ƠN ........................................................................................................ i
LỜI CAM ĐOAN.................................................................................................. ii
MỤC LỤC ............................................................................................................ iii
DANH MỤC CÁC KÍ HIỆU, CÁC CHỮ VIẾT TẮT ......................................... v
DANH MỤC CÁC BẢNG................................................................................... vi
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ ............................................................. vii
MỞ ĐẦU ............................................................................................................... 1
Chương 1. GIỚI THIỆU BÀI TỐN ................................................................... 4
1.1. Bài tốn tóm tắt văn bản............................................................................. 4
1.2. Bài toán xây dựng mục lục cho văn bản .................................................... 4
1.3. Phương hướng giải quyết bài toán ............................................................. 5
1.4. Các cơng trình liên quan ............................................................................ 6
Chương 2. PHÂN ĐOẠN VĂN BẢN VÀ SINH TIÊU ĐỀ ................................ 8
2.1. Phân đoạn văn bản...................................................................................... 8
2.2. Các phương pháp phân đoạn văn bản ........................................................ 9
2.2.1. Sử dụng mối liên kết từ vựng .............................................................. 9
2.2.2. Sử dụng mơ hình nhát cắt cực tiểu .................................................... 14
2.3. Sinh tiêu đề cho văn bản .......................................................................... 17
2.4. Các phương pháp sinh tiêu đề cho văn bản.............................................. 18
2.4.1. Phương pháp trích chọn cụm từ ........................................................ 18
2.4.2. Phương pháp hai pha ......................................................................... 20
2.5. Tóm tắt chương hai .................................................................................. 20
Chương 3. XÂY DỰNG MỤC LỤC CHO VĂN BẢN...................................... 22
3.1. Mơ hình tích hợp thuật tốn ..................................................................... 22
3.2. Đảm bảo tính hợp lí của mục lục ............................................................. 23
3.3. Các phương pháp đánh giá ....................................................................... 24
3.3.1. Đánh giá thuật toán phân đoạn.......................................................... 24
3.3.2. Đánh giá thuật tốn sinh tiêu đề ........................................................ 27
3.4. Tóm tắt chương ba ................................................................................... 27
iv
Chương 4. THỬ NGHIỆM VÀ ĐÁNH GIÁ ...................................................... 29
4.1. Môi trường thử nghiệm ............................................................................ 29
4.2. Dữ liệu thử nghiệm .................................................................................. 30
4.3. Quá trình thử nghiệm ............................................................................... 33
4.4. Kết quả thử nghiệm .................................................................................. 33
4.4.1. Kết quả phân đoạn văn bản ............................................................... 33
4.4.2. Kết quả sinh tiêu đề ........................................................................... 34
4.5. Đánh giá thử nghiệm ................................................................................ 35
4.5. Phương hướng cải tiến ............................................................................. 36
4.6. Tóm tắt chương bốn ................................................................................. 37
KẾT LUẬN ......................................................................................................... 38
TÀI LIỆU THAM KHẢO ................................................................................... 39
v
DANH MỤC CÁC KÍ HIỆU, CÁC CHỮ VIẾT TẮT
STT Kí hiệu/Viết tắt
1
TF
Diễn giải
Term Frequency
Tần suất của từ / cụm từ trong một văn bản
2
TF * IDF
Term Frequency * Inverse Document Frequency
Trọng số của từ / cụm từ được tính theo tần suất trong văn
bản và tần suất văn bản chứa từ / cụm từ đó.
3
DUC
Document Understanding Conferences
Hội nghị chuyên về hiểu văn bản.
4
ACL
The Association for Computational Linguistics
Hiệp hội xử lí văn bản trên máy tính.
5
SVO
Subject – Verb – Object
Cấu trúc ngữ pháp Chủ ngữ – Động từ – Tân ngữ.
vi
DANH MỤC CÁC BẢNG
Bảng 1. Biểu diễn vectơ của hai khối văn bản ví dụ ........................................... 11
Bảng 2. Danh sách các công cụ phần mềm sử dụng để thử nghiệm ................... 29
Bảng 3. Cấu trúc văn bản thử nghiệm ................................................................. 30
Bảng 4. Danh sách từ dừng ................................................................................. 31
Bảng 5. Tập nhãn từ loại (tập mở) ...................................................................... 32
Bảng 6. Tập nhãn từ loại (tập đóng) ................................................................... 32
Bảng 7. Kết quả phân đoạn văn bản.................................................................... 33
Bảng 8. Sinh tiêu đề cho phân đoạn gốc ............................................................. 34
Bảng 9. Sinh tiêu đề cho phân đoạn của C99...................................................... 35
Bảng 10. Sinh tiêu đề cho phân đoạn của jTextTiling ........................................ 35
vii
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ
Hình 1. Đồ thị biểu diễn sự thay đổi độ đo tương tự .......................................... 12
Hình 2. Đồ thị dotplotting cho một văn bản ....................................................... 13
Hình 3. Phân bố độ dài tiêu đề văn bản theo Reuters-1997 ................................ 18
Hình 4. Ví dụ đánh giá thuật tốn phân đoạn...................................................... 25
Hình 5. Cách xác định tham số cho độ đo Pk ...................................................... 26
Hình 6. Kết quả phân đoạn văn bản .................................................................... 34
1
MỞ ĐẦU
Hiện nay, lượng văn bản được số hoá đang tăng lên nhanh chóng và đặc
biệt được phổ biến rộng rãi cùng với sự tăng trưởng của Internet. Các văn bản
này thuộc nhiều dạng khác nhau như văn bản chữ viết, văn bản âm thanh và văn
bản hình ảnh. Nguồn thơng tin khổng lồ này vừa mang lại lợi ích giúp con người
tiếp cận và khai thác được nhiều thông tin hơn, nhưng mặt khác cũng gây khó
khăn cho cơng việc lựa chọn và tổng hợp thông tin. Lĩnh vực xử lí ngơn ngữ tự
nhiên (xử lí ngơn ngữ trên máy tính một cách tự động) ra đời nhằm giải quyết
phần nào sự khó khăn này.
Lĩnh vực xử lí ngơn ngữ tự nhiên đã đặt ra hàng loạt bài toán nhằm giải
quyết các khó khăn và trợ giúp con người xử lí văn bản tốt hơn như: tìm kiếm
văn bản, phân lớp văn bản, rút trích thơng tin, tóm tắt văn bản, hệ thống hỏiđáp,… Các hệ thống thông tin trực tuyến như Google, Yahoo!, MSN,… đã thể
hiện được các kết quả nghiên cứu giải quyết các bài toán này. Ví dụ như máy
tìm kiếm Google đảm nhận việc tìm kiếm các văn bản theo yêu cầu của người
dùng, trích ra các đoạn văn bản liên quan đến yêu cầu, tóm tắt lại dựa trên các
thơng tin đó và hiển thị cho người dùng lựa chọn. Tuy chất lượng xử lí văn bản
chưa đạt được mức độ như con người nhưng sự lớn mạnh của các cỗ máy tìm
kiếm trên đã cho thấy tiềm năng và triển vọng thực sự của các bài tốn trong xử
lí ngơn ngữ tự nhiên.
Tóm tắt văn bản là một bài tốn trong xử lí ngơn ngữ tự nhiên, đó là “một
q trình thu gọn văn bản đầu vào thành văn bản tóm tắt thơng qua việc cô
đọng nội dung bằng cách lựa chọn và/hoặc tổng hợp những thông tin quan
trọng trong văn bản đầu vào” [18]. Trong thời gian gần đây, tóm tắt văn bản
đang nhận được sự quan tâm rộng rãi của cộng đồng nghiên cứu trên thế giới với
sự tăng trưởng về số bài báo có liên quan trong các hội nghị DUC1 2001-2007,
ACL2 2001-2007,…; sự phát triển của các hệ thống tóm tắt văn bản3 như MEAD,
LexRank, Text Analyst (Megaputer), Text Analysis (IBM Japan), Microsoft
Word,… Rất nhiều bài toán nhỏ của tóm tắt văn bản đã được đặt ra và giải quyết
[18] thông qua các hội nghị và phần mềm kể trên.
1
/>
2
/>
3
/>
2
Một trong những vấn đề được quan tâm nghiên cứu gần đây là xây dựng
mục lục cho văn bản một cách tự động [2, 5]. Đây là một bài toán tóm tắt văn
bản, trong đó các thơng tin quan trọng của tài liệu được định nghĩa là tiêu đề của
các đoạn văn bản và được thể hiện dưới dạng danh sách ở mục lục của văn bản.
Cấu trúc mục lục là một cấu trúc phổ biến ở trong các văn bản dài mà đặc biệt là
các cuốn sách, nó giúp người đọc tìm kiếm chủ đề quan tâm và định vị được vị
trí của chủ đề đó trong văn bản. Đối với các văn bản âm thanh, hình ảnh, việc
xây dựng được mục lục cho văn bản là rất cần thiết vì những văn bản dạng này
hầu như khơng có sẵn mục lục để định vị các phân đoạn thông tin khác nhau [3,
10, 18, 20]. Việc xây dựng mục lục cho văn bản gồm hai bước, bước thứ nhất là
phân đoạn văn bản, tức là phân văn bản thành các đoạn rời rạc, nối tiếp nhau,
mỗi đoạn nói về một chủ đề tương đối khác nhau [2, 4, 6, 15, 16, 20] và bước
thứ hai là sinh tiêu đề cho các đoạn văn bản, tức là sinh một cụm từ ngắn thể
hiện được chủ đề chính của đoạn văn [3, 10, 17, 28]. Trong [5], các tác giả đã
trình bày và thử nghiệm xây dựng mục lục cho văn bản, tuy nhiên bài báo mới
dừng lại ở việc giải quyết nửa sau của bài toán xây dựng mục lục cho văn bản,
tức là sinh tiêu đề và xây dựng cấu trúc mục lục với việc sử dụng cấu trúc phân
đoạn sẵn có của văn bản. Hơn thế nữa, mơ hình trong [5] là mơ hình học giám
sát, địi hỏi phải có dữ liệu huấn luyện trong khi loại dữ liệu này rất thiếu đối với
bài toán được đề cập.
Với việc lựa chọn đề tài “Tự động sinh mục lục cho văn bản”, luận văn
này hướng tới việc tích hợp hai bước phân đoạn và sinh tiêu đề trong quá trình
xây dựng mục lục cho văn bản một cách tự động. Trong luận văn này, các bài
toán của từng bước được nghiên cứu chi tiết; phương pháp tích hợp hai bước với
nhau được đề xuất và tiến hành thử nghiệm thực tế trên văn bản khoa học. Kết
quả thực nghiệm khả quan của luận văn đã cho thấy tính khả thi và triển vọng
của bài tốn này. Ngồi ra trong luận văn, tác giả cũng đưa ra những phương
hướng cải tiến cùng cơ sở khoa học của nó để làm tiền đề cho các nghiên cứu
tiếp theo.
Ngoài phần mở đầu và kết luận, kết cấu của luận văn bao gồm 4 chương:
- Chương 1 “Giới thiệu bài toán” sẽ giới thiệu bài tốn tóm tắt văn bản
nói chung và bài tốn xây dựng mục lục cho văn bản nói riêng; phân
tích các cơng trình có liên quan và đưa ra các thức giải quyết bài toán
của luận văn.
- Chương 2 “Phân đoạn văn bản và sinh tiêu đề” sẽ tiến hành nghiên
cứu và trình bày các phương pháp và thuật toán tiêu biểu được sử dụng
3
trong các bước phân đoạn và sinh tiêu đề trong quá trình xây dựng
mục lục cho văn bản.
- Chương 3 “Xây dựng mục lục cho văn bản” sẽ phân tích và đề xuất
phương án tích hợp các thuật tốn của các bước để giải quyết bài tốn
chính của luận văn; đề xuất một số hướng cải tiến và cơ sở lí luận của
các cải tiến đó; và trình bày các phương pháp đánh giá.
- Chương 4 “Thử nghiệm và đánh giá” sẽ trình bày quá trình thử
nghiệm của luận văn cùng các kết quả đạt được, đồng thời phân tích và
đánh giá các kết quả đó để làm tiền đề cho các đề xuất cải tiến.
4
Chương 1
GIỚI THIỆU BÀI TỐN
1.1. Bài tốn tóm tắt văn bản
Tóm tắt văn bản là một bài tốn đã được đặt ra từ rất lâu, đó là “một q
trình thu gọn văn bản đầu vào thành văn bản tóm tắt thông qua việc cô đọng nội
dung bằng cách lựa chọn và/hoặc tổng hợp những thông tin quan trọng trong
văn bản đầu vào” [18]. Trước kia công việc này thường được thực hiện một
cách thủ cơng bởi chính tác giả hoặc của người thủ thư. Tuy nhiên khi lượng văn
bản được số hố ngày càng nhiều thì vấn đề tóm tắt văn bản một cách tự động đã
trở nên rất cần thiết. Năm 1958, trong bài báo của mình [19], Luhn đã trình bày
phương pháp tóm tắt tự động cho các bài báo kĩ thuật sử dụng phương pháp
thống kê thông qua tần suất và phân bố của các từ trong văn bản. Cho đến gần
đây, sự đột phá trong công nghệ máy tính đã giúp các bài tốn xử lý ngôn ngữ tự
nhiên trở nên “thực tế” hơn. Theo [18], ngày càng có nhiều nghiên cứu về tóm
tắt văn bản và những tóm tắt này được chia ra làm hai hướng nghiên cứu chính:
tiếp cận theo hướng ngơn ngữ học (dựa trên luật), tiếp cận theo hướng thống kê
hoặc kết hợp cả hai.
Tóm tắt văn bản tự động bị ảnh hưởng bởi rất nhiều yếu tố như: thể loại
văn bản, phong cách viết, các sử dụng từ, cấu trúc câu,… Những yếu tố này tạo
nên sự khác biệt rất lớn giữa các văn bản khác nhau. Do đó việc xây dựng một
cơng cụ tóm tắt tổng qt là một cơng việc khó. Vì vậy, các bài tốn được giải
quyết trong tóm tắt văn bản thường chỉ hướng đến một kiểu văn bản cụ thể hoặc
một kiểu tóm tắt cụ thể [14].
1.2. Bài toán xây dựng mục lục cho văn bản
Hiện nay, các nghiên cứu về tóm tắt văn bản hầu hết tập trung vào việc xử
lí các văn bản ngắn, đặc biệt là các mẩu tin tức, bài viết ngắn hoặc tập trung cho
các văn bản thuộc một lĩnh vực cụ thể như văn bản y tế, văn bản khoa học,… [5,
18]. Các văn bản loại này hầu hết chỉ tập trung nói về một vấn đề rất cụ thể và
khơng có sự phân biệt về chủ đề giữa các phần trong văn bản. Còn đối với các
văn bản dài hơn, mà ở đây là loại văn bản bao gồm nhiều phần, mỗi phần nói về
một chủ đề cụ thể và cả văn bản nói về một chủ đề rộng hơn thì lượng nghiên
cứu cịn ít [5].
Trong luận văn này, một bài tốn tương đối mới trong tóm tắt văn bản sẽ
được đề cập và nghiên cứu, đó là bài toán xây dựng mục lục cho văn bản một
5
cách tự động. Mục lục cho một văn bản là một khái niệm rất phổ biến và xuất
hiện trong hầu hết các tài liệu có nhiều phần, đặc biệt là trong các tạp chí hay
quyển sách. Khi người sử dụng gặp một văn bản dài gồm nhiều phần khác nhau
thì thơng thường họ khơng đọc tồn bộ văn bản mà sẽ đi tìm mục lục hoặc một
hình thức tóm tắt nào đó để nhanh chóng nắm được ý chính của một văn bản.
Tuy nhiên, mục lục vẫn quan trọng và có ý nghĩa hơn cả vì ngồi khả năng cung
cấp thông tin về chủ đề của mỗi đoạn văn bản, nó cịn có giúp người đọc có thể
định vị được vị trí của đoạn thơng tin tương ứng trong tài liệu.
Xét về mặt cấu trúc, mục lục có cấu trúc phân cấp nhằm chia nhỏ hơn các
phần trong một tài liệu dài. Cấu trúc đó thường là phần, chương, mục,… Tuy
nhiên qua khảo sát thực tế, các tài liệu có số phần khơng nhiều lắm (dưới 10
phần) thì người ta thường sử dụng mục lục chỉ có một cấp. Trong luận văn này,
dựa trên thuật toán giải quyết vấn đề thì mục lục được chia làm hai loại: mục lục
tuyến tính (một cấp) và mục lục phân cấp (đa cấp). Và trong luận văn này, tôi
tập trung giải quyết bài tốn xây dựng mục lục tuyến tính (một cấp).
Bài tốn xây dựng mục lục cho văn bản liên quan đến nhiều bài toán khác
nhau như: Tách câu, tách từ, phân cụm, gán nhãn chức năng từ loại, tìm cụm
danh từ. Các bài tốn này hầu hết đã được xử lí với chất lượng khá tốt trong văn
bản tiếng Anh. Trong luận văn này, tôi chỉ đề cập đến việc sử dụng kết quả của
các bài toán này để giải quyết bài tốn lớn hơn mà khơng đi trình bày từng bài
tốn đó.
1.3. Phương hướng giải quyết bài tốn
Như đã đề cập ở phần trước, mục lục của văn bản sẽ bao gồm tiêu đề và vị
trí của các đoạn tương ứng cho văn bản. Do đó với một văn bản cho trước thì để
có thể tiến hành xây dựng mục lục, chúng ta cần những bước sau:
- Phân đoạn văn bản (Text Segmentation): phân văn bản thành các
đoạn độc lập và nối tiếp nhau với nội dung các phần có sự khác biệt về
mặt ngữ nghĩa và do đó có sự khác biệt về mặt chủ đề.
- Sinh tiêu đề (Title Generation): sinh ra các tiêu đề ngắn gọn, giàu
thông tin cho đoạn văn bản tương ứng hay nói cách khác là tìm ra chủ
đề của đoạn văn bản và trình bày dưới dạng ngắn gọn.
Phương pháp giải quyết vấn đề của luận văn là chia quá trình xây dựng
mục lục thành hai giai đoạn tương ứng với hai bước trên.
Bài tốn thứ nhất, phân đoạn văn bản, có thể được giải quyết bằng cách sử
dụng cấu trúc phân đoạn sẵn có của văn bản (chương, mục, mục con,…) [5]
6
hoặc sử dụng một phương pháp phân đoạn văn bản tự động [2, 4, 6, 15, 16, 20].
Trong luận văn này, phương pháp phân đoạn tự động sẽ được áp dụng với một
số cải tiến để đạt được chất lượng tốt hơn.
Bài toán thứ hai, sinh tiêu đề cho một đoạn văn bản, có thể sử dụng rất
nhiều phương pháp có sẵn để giải quyết [2, 3, 10, 17, 28]. Các phương pháp này
được chia làm hai hướng chính, hướng thứ nhất sẽ tìm cách trích ra các cụm từ
thể hiện ý nghĩa của toàn đoạn và hướng thứ hai là trích ra các từ quan trọng
trong văn bản và tìm cách ghép cặp với nhau để đạt được tiêu đề “tốt nhất”. Mỗi
phương pháp có ưu và nhược điểm riêng và sẽ được phân tích trong Chương 2.
Tuy nhiên, luận văn sẽ sử dụng phương pháp thứ nhất cho thực nghiệm và
phương pháp thứ hai sẽ để lại làm hướng phát triển tiếp theo cho đề tài.
Phần tiếp theo sẽ trình bày một số cơng trình liên quan được sử dụng
trong q trình thực hiện luận văn.
1.4. Các cơng trình liên quan
Trong phần này, một số cơng trình liên quan đến đề tài luận văn sẽ được
đề cập, tuy nhiên, các bài toán cơ sở như tách câu, tách từ, gán nhãn từ loại, tìm
cụm danh từ,… sẽ khơng được đề cập do đây không phải là mục tiêu chính của
luận văn, hơn nữa độ chính xác của các bài tốn đó đã đạt được ở mức rất cao
đối với tiếng Anh (trên 90%), do đó hồn tồn có thể sử dụng làm các bước nền
để giải quyết các bài tốn lớn hơn.
Về khía cạnh độ dài và thể loại văn bản, trong khi hầu hết các nghiên cứu
hiện tại tập trung vào các văn bản ngắn thì đã có một số hướng tiếp cận được
triển khai để tóm tắt những văn bản dài hơn. Hầu hết các cách tiếp cận này tập
trung vào một miền ngữ nghĩa cụ thể như văn bản y tế hoặc tài liệu khoa học.
Với việc đưa ra các giả thiết mạnh về cấu trúc văn bản đầu vào và định dạng đầu
ra, các cách tiếp cận này đã thu được những kết quả tương đối khả quan. Ví dụ,
[27] tóm tắt các văn bản khoa học bằng cách lựa chọn những yếu tố tu từ
(rhetorical elements) thường được trình bày trong các đoạn tóm tắt của tài liệu
khoa học. [11] trình bày cách tiếp cận sinh tóm tắt của các tài liệu y tế bằng việc
sử dụng một số cấu trúc mẫu trong lựa chọn nội dung. Tuy nhiên, trong luận văn
này, tôi sử dụng cách tiếp cận độc lập thể loại, tức là tóm tắt văn bản mà khơng
sử dụng các yếu tố đặc trưng liên quan để thể loại văn bản.
Về bài tốn phân đoạn văn bản, đã có khá nhiều cơng trình nghiên cứu
liên quan đến vấn đề này [2, 4, 6, 15, 16, 20] . Hầu hết các công trình đều chỉ tập
trung nghiên cứu bài tốn phân đoạn văn bản một cấp, hay nói cách khác là phân
7
đoạn văn bản tuyến tính. Trong đó đáng kể nhất phải nói tới cơng trình [15],
cơng trình này là cơ sở cho rất nhiều cơng trình khác liên quan đến bài tốn này,
chi tiết sẽ được trình bày ở Chương 2. Trong luận văn này, tơi chủ yếu phân tích
và sử dụng cơng trình [15] với việc cài đặt cụ thể và tích hợp một số cải tiến
được đề xuất trong Chương 3.
Về bài tốn sinh tiêu đề, các cơng trình liên quan đến vấn đề này đã có rất
nhiều, tiêu biểu như [2, 3, 10, 17, 28]. Tuy nhiên, các cơng trình này chủ yếu
được sử dụng để sinh tiêu đề cho một tài liệu đơn lẻ trong khi bài toán của
chúng ta là sinh tiêu đề cho nhiều đoạn văn bản có sự liên kết và ràng buộc với
nhau về mặt nội dung. Luận văn sẽ tiến hành đề xuất một mơ hình sinh tiêu đề
có khả năng đảm bảo tương đối tính thống nhất giữa các tiêu đề được sinh ra.
Mơ hình này sử dụng kết hợp cả phương pháp lựa chọn lẫn phương phương
pháp sử dụng các đặc trưng về ngữ pháp.
Đối với bài toán xây dựng mục lục cho văn bản, trong [2, 5] nêu ra bài
toán này. Tuy nhiên, các tác giả chỉ tập trung giải quyết bài toán thứ hai của việc
xây dựng mục lục cho văn bản, đó là sinh tiêu đề cho đoạn văn bản. Trong [2],
các tác giả sinh tiêu đề theo hướng trích chọn cụm danh từ quan trọng nhất làm
tiêu đề cho văn bản và chất lượng theo đánh giá thực nghiệm thì đạt kết quả rất
khả quan, tuy nhiên việc phân đoạn văn bản của [2] tỏ ra thực sự không hiệu quả
do số lượng đoạn sinh ra quá lớn và số câu trung bình trên một đoạn chỉ là 2-3
câu, điều này là không phù hợp với thực tế trong các văn bản. Còn trong [5], các
tác giả sử dụng cấu trúc phân đoạn sẵn có của văn bản và chỉ tập trung vào bước
sinh mục lục cho văn bản. Kết quả đạt được theo đánh giá là khá tốt tuy nhiên
phương pháp này sử dụng thuật tốn học có giám sát trong khi dữ liệu đối với
bài tốn này hiện nay rất ít nên sẽ khó có thể áp dụng được trên nhiều loại văn
bản khác nhau.
Trong chương tiếp theo, luận văn sẽ trình bày về một số phương pháp
được sử dụng để giải quyết bài toán phân đoạn văn bản và sinh tiêu đề cho văn
bản, đồng thời phân tích ưu, nhược điểm của các phương pháp đó.
8
Chương 2
PHÂN ĐOẠN VĂN BẢN VÀ SINH TIÊU ĐỀ
2.1. Phân đoạn văn bản
Bài tốn phân đoạn văn bản có thể được hiểu là bài toán với một văn bản
cho trước, hãy xác định những vị trí mà ở đó chủ đề thay đổi [15, 16]. Đối với
các văn bản ngắn như bài báo hay bản tin thường chỉ có một chủ đề xuyên suốt
toàn văn bản, sự phân lập về mặt chủ đề giữa các đoạn hầu như khơng có. Tuy
nhiên trong các văn bản dài hơn, như các văn bản khoa học thì có rất nhiều phần
khác nhau, mỗi có một chủ đề riêng tuy các phần đều hướng đến cùng mục đích
là giải quyết vấn đề được đặt ra trong văn bản. Bài toán này đã được giải quyết
theo một vài hướng khác nhau như sử dụng mối liên kết từ vựng [2, 6, 15, 16],
sử dụng mô hình thống kê [4] hay gần đây là phương pháp áp dụng mơ hình đồ
thị [20]. Trong phần tiếp theo, luận văn sẽ trình bày chi tiết hai phương pháp tiêu
biểu dùng trong phân đoạn văn bản được nêu ra trong [15, 20] cùng các cải tiến
của các phương pháp đó.
Bài tốn phân đoạn văn bản khơng chỉ có ý nghĩa với các văn bản thơng
thường mà nó cịn có ý nghĩa lớn với các bài toán liên quan đến văn bản đa
phương tiện dạng âm thanh hay hình ảnh [3, 20]. Ví dụ, với một đoạn băng ghi
lại bài phát biểu chào mừng năm học mới của hiệu trưởng, có rất nhiều phần
khác nhau như: chào mừng học sinh mới, sơ kết năm học cũ và phương hướng
năm học mới. Các phần này không được phân tách một cách rõ ràng như trong
văn bản viết, do đó sẽ khó khăn hơn trong vấn đề phân đoạn. Phương pháp
thường được sử dụng là phân tích các đặc trưng về khoảng lặng giữa các phần,
âm điệu thay đổi khi chuyển phần,… hay có thể sử dụng một module nhận dạng
giọng nói sau đó sử dụng các phương pháp phân đoạn văn bản mà luận văn sẽ
trình bày. Hay trong một đoạn băng video dài, người ta có thể quay nhiều lần
khác nhau ở những thời điểm khác nhau và do đó với những chủ đề khác nhau
để tiết kiệm đoạn băng. Việc tự động tìm ra các vị trí thay đổi chủ đề một cách
tự động thực sự có ý nghĩa khi biên tập.
Khi tiến hành phân đoạn văn bản, chúng ta sẽ gặp phải những vị trí mà sự
thay đổi chủ đề là “lớn” (ví dụ, chuyển hẳn sang chủ đề khác) hoặc sự thay đổi
chủ đề là “nhỏ” (ví dụ, vẫn nói về chủ đề lớn nhưng theo các cách tiếp cận khác
nhau). Điều đó làm nảy sinh bài toán phân đoạn văn bản đa cấp [2, 5]. Với bài
toán này, một văn bản ban đầu được chia thành các đoạn lớn mang các chủ đề
riêng, sau đó mỗi đoạn văn bản này lại được phân đoạn tiếp để thu được các chủ
9
đề nhỏ hơn, giúp người đọc dễ theo dõi hơn. Việc giải quyết bài tốn này có thể
đi theo một trong hai hướng tiếp cận: phân đoạn kiểu đệ quy, tức là phân đoạn
theo từng mức một, hoặc phân đoạn một lần tức là chỉ một lần áp dụng thuật
toán mà ta thu được văn bản đã được phân thành vài cấp.
2.2. Các phương pháp phân đoạn văn bản
2.2.1. Sử dụng mối liên kết từ vựng
Phương pháp phân đoạn văn bản sử dụng mối liên kết từ vựng là phương
pháp phân đoạn dựa trên sự khác nhau trong việc sử dụng từ, đặc biệt là các tính
chất lặp lại của từ, giữa các đoạn văn bản khác nhau: nếu có sự khác biệt lớn
trong việc sử dụng từ trong các đoạn văn bản ở hai phía của một vị trí phân tách
thì đó được coi là đường biên. Tập hợp các đường biên sẽ phân văn bản thành
các đoạn khác nhau.
Điển hình cho phương pháp này là hệ thống TextTiling của Hearst [15,
16]. Trong hệ thống của mình, Hearst đã sử dụng ý tưởng về mối quan hệ liên
kết từ vựng trong văn bản để tìm ra những vị trí mà ở đó xảy ra sự thay đổi đồng
thời của rất nhiều yếu tố như không gian, thời gian, cấu trúc, sự kiện,… và sự
thay đổi này là đạt cực đại tại điểm đó. Trong TextTiling, Heart chia văn bản
thành các “tile”. Các tile mang ý nghĩa tương đương với các đoạn được hình
thành do quá trình phân đoạn văn bản. Sau đây, luận văn sẽ trình bày tóm tắt
thuật tốn của Hearst dùng để tìm ra các phân đoạn trong một văn bản.
Các nghiên cứu trong ngôn ngữ học và khoa học máy tính, đặc biệt là
trong tiếng Anh, cho thấy rằng sự lặp lại của các thuật ngữ, khái niệm chỉ ra mối
liên kết chặt chẽ về mặt ngữ nghĩa. Điều đó đã chỉ ra rằng sự lặp lại của các khái
niệm sẽ rất có ích trong việc xác định cấu trúc phân đoạn của văn bản và chúng
ta sẽ sử dụng yếu tố lặp lại của các khái niệm với vai trò là yếu tố chỉ ra mối liên
kết từ vựng [15, 22].
Thuật toán này là một mở rộng của thuật tốn được trình bày trong [22]
với khả năng ghi lại chuỗi các khái niệm lặp lại. Thuật toán xác định đường biên
bằng cách xem xét các vị trí mà ở đó có sự kết thúc của một chuỗi khái niệm và
bắt đầu một chuỗi khái niệm mới.
Thuật toán bao gồm các bước:
- Tokenization.
- Xác định độ tương tự.
- Nhận diện biên.
10
Tokenization là quá trình chia văn bản đầu vào thành các đơn vị từ vựng
độc lập (token). Trong quá trình này, văn bản được chia thành các “câu giả” với
độ dài cố định w cho trước (chứ không dùng các câu được xác định với cú pháp
hoàn chỉnh) mặc dù điều này sẽ gây ra vấn đề chuẩn hoá trong bước cuối khi xác
định biên chính xác. Q trình này sẽ tạo ra các nhóm token và được gọi là
chuỗi token. Các kết quả thực nghiệm cho thấy độ dài w là 20 sẽ phù hợp với
hầu hết các loại văn bản khác nhau. Các token được phân tích hình thái và được
lưu trong một bảng. Tương ứng với mỗi token là số thứ tự (đồng thời là chỉ số)
của chuỗi token và tần suất xuất hiện của các token tương ứng chuỗi token.
Đồng thời, vị trí các điểm ngắt đoạn (paragraph break) trong văn bản cũng được
lưu trữ lại. Những từ dừng và từ quá phổ biến cũng được loại ra trong q trình
phân tích hình thái (trong [15] khơng áp dụng q trình tinh giản này).
Bước tiếp theo sau quá trình tokenization là tiến hành so sánh độ tương tự
từ vựng của các cặp khối (block) liền kề của các chuỗi từ vựng. Một tham số
quan trọng khác của thuật tốn được đưa vào là kích thước khối (blocksize),
được định nghĩa là số các chuỗi token được nhóm lại cùng nhau để so sánh với
một nhóm chuỗi token liền kề khác. Giá trị này được kí hiệu là k thay đổi tuỳ
theo các văn bản khác nhau, tuy nhiên người ta thường lấy nó là độ dài trung
bình tính theo chuỗi token của các đoạn văn bản (paragraph). Trong thực tế, giá
trị k là 6 sẽ phù hợp với hầu hết các loại văn bản khác nhau. Các đoạn thực sự
trong văn bản không được sử dụng do độ dài của của các đoạn không đều nhau
và gây ra sự mất cân bằng trong quá trình so sánh.
Giá trị tương tự sẽ được tính cho tất cả các vị trí ở giữa các chuỗi token.
Nghĩa là tại mỗi vị trí i ở giữa các chuỗi token, độ tương tự sẽ được tính trên hai
khối, khối thứ nhất là các chuỗi token từ i k tới i và khối thứ hai là từ i 1 tới
i k 1 . Đây là cách tiếp cận theo kiểu cửa sổ trượt (sliding window), cách tiếp
cận này sẽ khiến mỗi chuỗi token được tính 2k lần.
Độ tương tự sim sẽ được tính theo độ đo cosin cho hai khối b1 và b2 với
độ dài k chuỗi token cho mỗi khối:
sim b1 , b2
w w
w
t
t
t ,b1
2
t ,b1
t ,b2
n
t 1
wt2,b2
Trong đó khái niệm t được tính trên tập tất cả các token thu được trong
quá trình tokenization và wt ,bi là trọng số được gán cho khái niệm t trong khối bi .
Ở đây, trọng số được tính đơn giản bằng tần suất của khái niệm tương ứng trong
khối (TF). Ngồi ra trọng số cịn có thể được tính theo cơng thức TF IDF
11
trong trường hợp có nhiều văn bản. Theo cơng thức trên thì nếu độ tương tự giữa
hai khối là cao thì chứng tỏ hai khối có nhiều khái niệm chung. Giá trị của độ đo
này nằm trong đoạn 0;1 .
Ví dụ ta có 2 khối với nội dung như sau:
Khối 1: I like apples.
Khối 2: Apples are good for you.
Khi biểu diễn dưới dạng vectơ, hai khối này có nội dung như sau:
Bảng 1. Biểu diễn vectơ của hai khối văn bản ví dụ
Từ
Apples
Are
For
Good
I
Like
You
Khối 1
1
0
0
0
1
1
0
Khối 2
1
1
1
1
0
0
1
Khi đó độ đo tương tự giữa 2 khối này có giá trị:
sim K1 , K 2
1 1 0 1 0 1 0 1 1 0 1 0 0 1
12 02 02 02 12 12 02 12 12 12 12 02 02 12
0.26
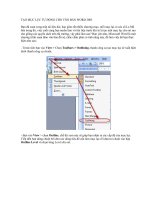
Độ đo tương tự này có thể được đồ thị hoá (biểu diễn dưới dạng đồ thị
đường) để có cái nhìn trực quan hơn về sự biến đổi trong đó trục x là số thứ tự
của token và trục y là giá trị độ đo tương tự. Tuy nhiên, do độ đo tương tự được
tính giữa hai khối b1 và b2 , trong đó b1 bao gồm các chuỗi token từ i k đến i
và b2 bao gồm các chuỗi token từ i 1 đến i k 1 nên độ đo sẽ rơi vào vị trí
giữa chuỗi token i và i 1 . Và trong thuật toán này, chúng ta sẽ sử dụng đồ thị
khác đi, với trục x là số thứ tự của điểm giữa của các chuỗi token. Để thuận tiện
cho việc tính tốn nên đồ thị được làm trơn bằng kĩ thuật làm trơn trung bình.
Trong thực nghiệm cho thấy, việc sử dụng kĩ thuật làm trơn trung bình với kích
thước cửa sổ là 3 thích hợp với hầu hết các văn bản và chỉ cần sử dụng một vịng
làm trơn.
Các vị trí biên được xác định thơng qua sự thay đổi trong chuỗi các độ đo
tương tự thu được ở bước trước hay một cách trực quan hơn là thông qua sự thay
đổi trên đồ thị. Số thứ tự của các điểm giữa của các chuỗi token không được sắp
xếp theo giá trị độ đo tương tự ở đó mà lại được sắp xếp phụ thuộc vào mức độ
dốc của đồ thị tại điểm đó so với các điểm xung quanh. Với một điểm giữa của
chuỗi token i, thuật toán sẽ xem xét độ đo tương tự tại điểm giữa của chuỗi
token bên trái của i miễn là giá trị của nó đang tăng. Khi giá trị so với bên trái
12
đạt cực đại, sự sai khác về độ đo tương tự giữa độ đo tại điểm đạt cực đại và độ
đo tại i được ghi lại. Công việc này được áp dụng tiếp tục với các điểm giữa của
các chuỗi token phía bên phải của i, độ tương tự của các điểm đó sẽ được kiểm
tra, miễn là chúng vẫn tiếp tục tăng. Độ cao tương đối của điểm cực đại so với
bên phải của i được cộng với độ cao tương đối của điểm cực đại so với điểm bên
trái (một điểm giữa xuất hiện tại điểm cực đại sẽ có độ đo bằng 0 vì cả hai điểm
bên cạnh đều khơng cao hơn nó). Độ đo mới này được gọi là độ sâu, tương ứng
với mức độ thay đổi xuất hiện ở hai phía của một điểm giữa của chuỗi token.
Đường biên của các phân đoạn sẽ được ấn định cho các điểm giữa của các chuỗi
token có độ đo tương ứng lớn nhất và sẽ được điều chỉnh để lấy được điểm ngăn
cách thực sự giữa các đoạn. Ngồi ra, thuật tốn cũng kiểm tra để đảm bảo các
phân đoạn không quá gần nhau. Theo thực nghiệm, nên có ít nhất 3 chuỗi token
giữa 2 đường biên. Điều này sẽ giúp ngăn những văn bản có thơng tin tiêu đề giả
và các đoạn chỉ có một câu. Một ví dụ cho trường hợp này chính là trong văn
bản có sẵn câu tiêu đề cho mỗi đoạn và thơng thường câu đó được ngăn với
đoạn văn bản tương ứng cũng bằng một dấu ngắt đoạn.
Độ tương tự
Làm mịn
Độ sâu
0.9000
0.7500
0.6000
0.4500
0.3000
0.1500
0.0000
0
5
10
15
20
25
30
35
40
45
50
55
60
Hình 1. Đồ thị biểu diễn sự thay đổi độ đo tương tự
Thuật tốn phải xác định có bao nhiêu phân đoạn (segment) sẽ được ấn
định cho một văn bản vì mỗi đoạn (paragraph) cũng có thể là một đường biên
tiềm năng. Khơng thể có một ngưỡng cố định cho trường hợp này vì nó phụ
thuộc theo kiểu văn bản và độ dài văn bản.
Hearst đã đưa ra một phương pháp tham ăn cho phép xác định số lượng
đường biên được ấn định phụ thuộc theo chiều dài văn bản và phụ thuộc theo
13
các độ đo tương tự trong văn bản đó: giá trị ngưỡng là một hàm của giá trị trung
bình và độ lệch chuẩn của độ sâu của văn bản sau khi được phân tích. Theo đó,
một đường biên được ấn định chỉ khi độ sâu của nó vượt qua s 2 , trong đó
s là giá trị trung bình cịn là độ lệch chuẩn.
Trong [16] trình bày phương pháp đánh giá giải thuật phân đoạn văn bản
thông qua độ chính xác và độ hồi tưởng, tuy nhiên các độ đo này tỏ ra khơng
thích hợp với bài toán phân đoạn văn bản. Trong [23], các tác giả đã trình bày
một độ đo khác WindowDiff là mở rộng của độ đo Pk do Beeferman đưa ra trong
[4]. Các độ đo này sẽ được trình bày trong Chương 3.
Một thuật toán tương tự thuật toán của Hearst là thuật toán của Reynar
[25]. Thuật toán này cũng thực hiện bước phân tích hình thái để loại bỏ các từ
dừng và từ phổ biến. Tuy nhiên ở bước sau, thuật toán này sử dụng các câu của
văn bản (cú pháp hoàn chỉnh) thay vì các câu giả với độ dài cố định như trong
thuật tốn của Hearst và sau đó tiến hành tính tốn độ tương tự trên tất cả các
cặp câu trong văn bản. Do đó thuật tốn này cịn được gọi là thuật tốn tính độ
tương tự tồn cục so với thuật tốn của Hearst tính tốn độ tương tự cục bộ (chỉ
tính trong vùng lân cận của văn bản). Tiếp đó, thuật tốn dựng một đồ thị theo kĩ
thuật dotplotting được trình bày trong [7]. Hình 2 là ví dụ của đồ thị dotplotting,
như ta thấy trên đồ thị, các vùng văn bản có độ tương tự cao sẽ sẽ hình thành các
khối đậm hơn (mật độ cao) và tập trung quanh đường chéo chính. Các đường kẻ
dọc là vị trí phân đoạn thực tế trong văn bản. Và như quan sát thấy trên đồ thị,
các điểm phân cách giữa các vùng có mật độ cao trên đường chéo chính hầu như
trùng với điểm phân đoạn thực tế của văn bản.
Hình 2. Đồ thị dotplotting cho một văn bản
14
Thuật toán này cũng sử dụng các mối liên kết từ vựng như của Hearst, chỉ
khác là thuật toán này sử dụng câu cú pháp thay vì câu giả và sử dụng kĩ thuật
dotplotting để xác định điểm biên thay vì dùng các phương pháp giải tích như
của Hearst. Theo [20], việc sử dụng chuỗi token có độ dài cố định hay thay đổi
có tác dụng gần như nhau, khơng có sự khác biệt đáng kể trong kết quả.
Ngồi ra, trong [6], các tác giả đã trình bày một phương pháp tổng hợp
dựa trên kĩ thuật của Hearst và kĩ thuật dotplotting cải tiến với việc áp dụng các
phép toán xử lí ảnh (nhân chập với một ma trận vng kích thước 3 3 ) để làm
rõ nét hơn vị trí của các đường biên và qua đó tìm được chính xác hơn vị trí
phân tách. Thuật tốn cịn được gọi là thuật toán C99. Trong phần thực nghiệm,
luận văn sẽ sử dụng công cụ C99 của Choi là một trong hai công cụ để phân
đoạn văn bản.
2.2.2. Sử dụng mơ hình nhát cắt cực tiểu
Ngồi việc sử dụng các mối liên kết từ vựng, chúng ta cịn có thể ứng
dụng lí thuyết đồ thị để giải quyết bài toán phân đoạn văn bản. Tiêu biểu cho
phương pháp này là mơ hình nhát cắt cực tiểu được trình bày trong [20]. Mơ
hình này sử dụng phép phân hoạch đồ thị thoả mãn điều kiện nhát cắt chuẩn hoá
(normalized-cut criterion) [26].
Trong khi các cách tiếp cận trước đây sử dụng độ đo tương tự để phân
đoạn thì trong mơ hình này, các tác giả mơ hình hố các đối tượng của bài tốn
thơng qua các đỉnh, cạnh và nhát cắt trên đồ thị. Mơ hình này sẽ tìm cách cực
đại độ tương tự trong mỗi phân đoạn và cực tiểu độ tương tự giữa các phân đoạn
khác nhau.
Mơ hình nhát cắt cực tiểu
Cho đồ thị G V , E là một đồ thị vơ hướng có trọng số trong đó V là
tập hợp các đỉnh tương ứng với các câu trong văn bản và E là tập hợp các cạnh
có trọng số. Trọng số w u, v định nghĩa độ tương tự giữa hai đỉnh u và v, trong
đó trọng số cao hơn chỉ ra rằng độ tương tự cao hơn. Chi tiết về cách thức xây
dựng đồ thị sẽ được trình bày ở phần xây dựng đồ thị.
Trước hết ta sẽ xem xét bài toán phân hoạch đồ thị thành hai tập hợp đỉnh
A và B. Chúng ta sẽ phải làm cực tiểu giá trị của nhát cắt mà giá trị này được
định nghĩa là tổng trọng số của các cạnh nối giữa hai tập hợp đỉnh. Hay nói cách
khác, ta muốn chia các câu thành hai tập hợp có độ phân biệt đạt cực đại bằng
cách chọn A và B để cực tiểu hoá giá trị nhát cắt: