BÀI GIẢNG ỨNG DỤNG TIN HỌC TRONG THIẾT KẾ THÍ NGHIỆM VÀ XỬ LÝ SỐ LIỆU (Phương pháp nghiên cứu nâng cao) part 7 pptx
Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây (333.32 KB, 5 trang )
31
hoc (tương tự như ví dụ ở hình 17). Chúng ta cũng chỉ tiến hành post hoc khi có
hơn 2 công thức thí nghiệm.
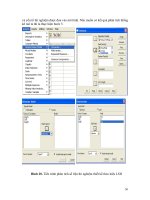
Hình 18. Tiến trình phân tích số liệu thí nghiệm thiết kế theo kiểu RCB
Kết quả phân tích được thể hiện ở bảng 13.
32
Bảng 13. Kết quả phân tích phương sai ảnh hưởng của giống đến năng suất
lúa trong thí nghiệm thiết kế theo kiểu RCB
Kiểm tra sự khác nhau giữa các nhóm (Tests of Between-Subjects Effects)
Biến phụ thuộc (Dependent Variable): Năng suất
Source Sum of Squares df Mean Square F Sig.
Corrected
Model 66,32 7,00 9,47 4,33 0,00
Intercept 1511,11 1,00 1511,11 690,38 0,00
Khối 9,22 2,00 4,61 2,11 0,13
Giống 57,10 5,00 11,42 5,22 0,00
Error 100,68 46,00 2,19
Total 1678,12 54,00
Corrected
Total 167,01 53,00
R
2
= ,397; (R
2
điều chỉnh= ,305)
Cách giải thích kết quả hoàn toàn tương tự như ví dụ 14 (kết quả ở bảng
10). Qua bảng 13 ta thấy rằng yếu tố giống đã ảnh hưởng đến năng suất lúa (P
<0,001). Như vậy, chúng ta bác bỏ giả thuyết H
0
và chấp nhận giả thuyết H
A
. Điều
này cũng có nghĩa là phải tiến hành phân tích post hoc để chỉ ra giống lúa nào sai
khác với giống lúa nào. Kết quả phân tích post hoc được thể hiện ở bảng 14.
Cách diễn giải kết quả hoàn toàn tương tự như kết quả phân tích post hoc ở
ví dụ 14 (bảng 11). Qua kết quả phân tích post hoc ở bảng 14 ta thấy rằng giống
lúa V6 có năng suất cao hơn tất cả các giống còn lạ
i, trong khi đó không có sự
khác biệt về năng suất lúa giữa các giống từ V1 đến V5.
Như đề cập ở trên trong mô hình phân tích số liệu của thí nghiệm thiết kế
theo kiểu RCB phải luôn luôn bao gồm cả yếu tố bị khống chế. Tuy nhiên, chúng
ta không quan tâm đến ảnh hưởng của yếu tố bị khống chế (yếu tố khối) đến biến
phụ thuộc. Một số phầ
n mềm tin học thậm chí không đưa kết quả về mức ý nghĩa
(giá trị P) của ảnh hưởng của yếu tố khối. Bảng 15 trình bày kết quả phân tích số
liệu theo kiểu RCB bằng phần mềm GENSTAT.
Trong phần 4, chúng tôi đã đề cập đến các bước phân tích phương sai. Một
trong những bước trong phân tích phương sai là lựa chọn mức độ tin cậy α. Trong
nông nghiệp nói riêng và khoa học nói chung thông thường người ta chấ
p nhận
một mức α là 0,05. Điều này không có nghĩa là chúng ta luôn luôn sử dụng mức α
= 0,05. Tùy theo mục đích và loại hình nghiên cứu (nghiên cứu trong phòng thí
nghiệm, nghiên cứu đồng ruộng) mà chúng ta có thể lựa chọn các mức α khác
nhau. Ví dụ thay vì α = 0,05 ta có thể chọn mức α = 0,01 hay 0,1. Điều này có thể
thực hiện trong SPSS. Trong các trình ứng dụng phân tich phương sai luôn luôn có
33
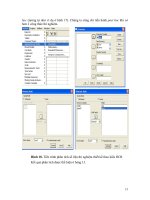
sự lựa chọn OPTION. Chúng ta có thể thay đổi mức độ tin cậy (significant level) α
trong OPTION (hình 19).
Bảng 14. Kết quả phân tích post hoc về ảnh hưởng của giống đến năng suất
lúa
Multiple Comparisons
Dependent Variable: giatri
LSD
-,86922 ,697423 ,219 -2,27306 ,53462
-,66289 ,697423 ,347 -2,06673 ,74095
-,15178 ,697423 ,829 -1,55562 1,25206
,16822 ,697423 ,810 -1,23562 1,57206
2,27933* ,697423 ,002 ,87549 3,68317
,86922 ,697423 ,219 -,53462 2,27306
,20633 ,697423 ,769 -1,19751 1,61017
,71744 ,697423 ,309 -,68639 2,12128
1,03744 ,697423 ,144 -,36639 2,44128
3,14856* ,697423 ,000 1,74472 4,55239
,66289 ,697423 ,347 -,74095 2,06673
-,20633 ,697423 ,769 -1,61017 1,19751
,51111 ,697423 ,467 -,89273 1,91495
,83111 ,697423 ,239 -,57273 2,23495
2,94222* ,697423 ,000 1,53838 4,34606
,15178 ,697423 ,829 -1,25206 1,55562
-,71744 ,697423 ,309 -2,12128 ,68639
-,51111 ,697423 ,467 -1,91495 ,89273
,32000 ,697423 ,649 -1,08384 1,72384
2,43111* ,697423 ,001 1,02727 3,83495
-,16822 ,697423 ,810 -1,57206 1,23562
-1,03744 ,697423 ,144 -2,44128 ,36639
-,83111 ,697423 ,239 -2,23495 ,57273
-,32000 ,697423 ,649 -1,72384 1,08384
2,11111* ,697423 ,004 ,70727 3,51495
-2,27933* ,697423 ,002 -3,68317 -,87549
-3,14856* ,697423 ,000 -4,55239 -1,74472
-2,94222* ,697423 ,000 -4,34606 -1,53838
-2,43111* ,697423 ,001 -3,83495 -1,02727
-2,11111* ,697423 ,004 -3,51495 -,70727
(J) giong
V2
V3
V4
V5
V6
V1
V3
V4
V5
V6
V1
V2
V4
V5
V6
V1
V2
V3
V5
V6
V1
V2
V3
V4
V6
V1
V2
V3
V4
V5
(I) giong
V1
V2
V3
V4
V5
V6
Mean
Difference
(I-J)
Std. Error Sig. Lower Bound Upper Bound
95% Confidence Interval
Based on observed means.
The mean difference is significant at the ,05 level.
*.
34
Bảng 15. Kết quả phân tích phương sai ảnh hưởng của giống đến năng suất
lúa trong thí nghiệm thiết kế theo kiểu RCB bằng phần mềm GENSTAT
Variate: Năng suất
Source of variation (N. biến động) d.f. s.s. m.s. v.r. F pr.
Khối stratum 2 9,221 4,610 2,11
Khối.*Units* stratum
giống 5 57,100 11,420 5,22 <,001
Residual (hiệu dư) 46 100,684 2,189
Total (tổng) 53 167,006
Hình 19. Thay đổi mức độ tin cậy α trong phân tích phương sai
5.3. Phân tích số liệu từ thí nghiệm kiểu LSD
Ví dụ 16. Một nhóm nghiên cứu quan tâm đến ảnh hưởng của các giống
ngô đến năng suất. Thí nghiệm được thiết kế theo kiểu LSD và kết quả thí nghiệm
được trình bày ở bảng 16. Hãy phân tích kết quả và chứng minh giả thuyết H
0
về
không có ảnh hưởng của giống ngô đến năng suất ngô.
Trước khi phân tích chúng ta phải xác định mô hình phân tích. Với kiểu
thiết kế thí nghiệm RCB một nhân tố, thì mô hình phân tích có thể như sau:
35
y
ijk
= µ + G
i
+ P
j
+ D
k
+ ε
ijk
• y
ij
= Biến phụ thuộc
• µ = Trung bình quần thể
•
G
i
= Ảnh hưởng của yếu tố hàng
•
P
j
= Ảnh hưởng của yếu tố cột
•
D
k
= Ảnh hưởng của yếu tố nghiên cứu
•
ε
ijk = Ảnh hưởng của ngẫu nhiên
Bảng 16. Năng suất (tấn/ha) của các giống ngô khác nhau, thiết kế thí
nghiệm theo kiểu LSD
Hàng Cột Giống Năng suất
h1 c1 B 1,64
h1 c2 D 1,21
h1 c3 C 1,425
h1 c4 A 1,345
h2 c1 C 1,457
h2 c2 A 1,185
h2 c3 D 1,4
h2 c4 B 1,29
h3 c1 A 1,67
h3 c2 C 0,71
h3 c3 B 1,665
h3 c4 D 1,18
h4 c1 D 1,565
h4 c2 B 1,29
h4 c3 A 1,655
h4 c4 C 0,66
Khi chúng ta đã rõ ràng về mô hình phân tích thì chúng ta có thể tiến hành
phân tích theo các bước như sau :
• Bước 1 : Nạp số liệu vào SPSS
• Bước 2: Vào trình ứng dụng General Linear Model-Univariate (hình
19.). Chúng ta sử dụng General Linear Model -Multivariate khi có nhiều biến phụ
thuộc. Chú ý biến phụ thuộc ở đây là biến định lượng.
• Bước 3 : Khai báo biến phụ thuộc (dependent variable) và biến độc
lập (fixed factors)(hình 20). Chúng ta có thể thấy rằng cả yếu tố hàng, yếu tố
cột